



Tonic.ai was born out of a very tangible, practical need: equipping developers with high-quality, realistic data for development and testing. This may make us sound like just another developer tool, but at the core of that need is our belief for why it truly matters. We wholeheartedly believe that data privacy is a human right.
It isn’t just about complying with the latest regulation. It’s about helping organizations treat data the way we’d like our own data to be treated. With the ever-expanding presence of AI, the importance of safe data handling is only more urgent.
Bringing together years of expertise in data analytics, database management, and data privacy, we understand the challenges standing in the way of effective, responsible data use. Our team is uniquely equipped to solve these challenges, and in the long run, the solutions we’re building for software and AI development stand to benefit us all.




.avif)
.avif)























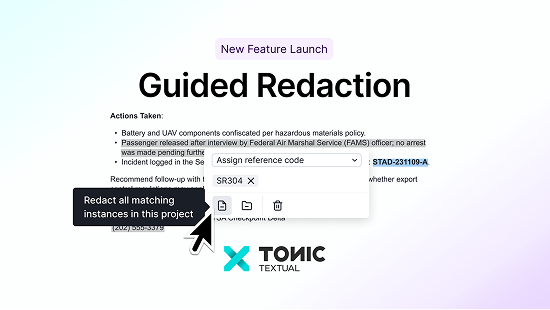
.png)


.png)












.avif)


