Expert insights on synthetic data
Blog posts
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.
Generative AI
Data privacy
Tonic Textual

Data privacy
Generative AI
Financial services
Tonic Textual
.png)
Test data management
Data de-identification
Tonic Structural
Tonic Fabricate

Test data management
Data de-identification
Tonic Structural
Tonic Fabricate

Data de-identification
Data privacy
Healthcare
Tonic Structural
Tonic Textual
Tonic Fabricate

Data privacy
Data de-identification
Tonic Fabricate
Tonic Structural
Tonic Textual
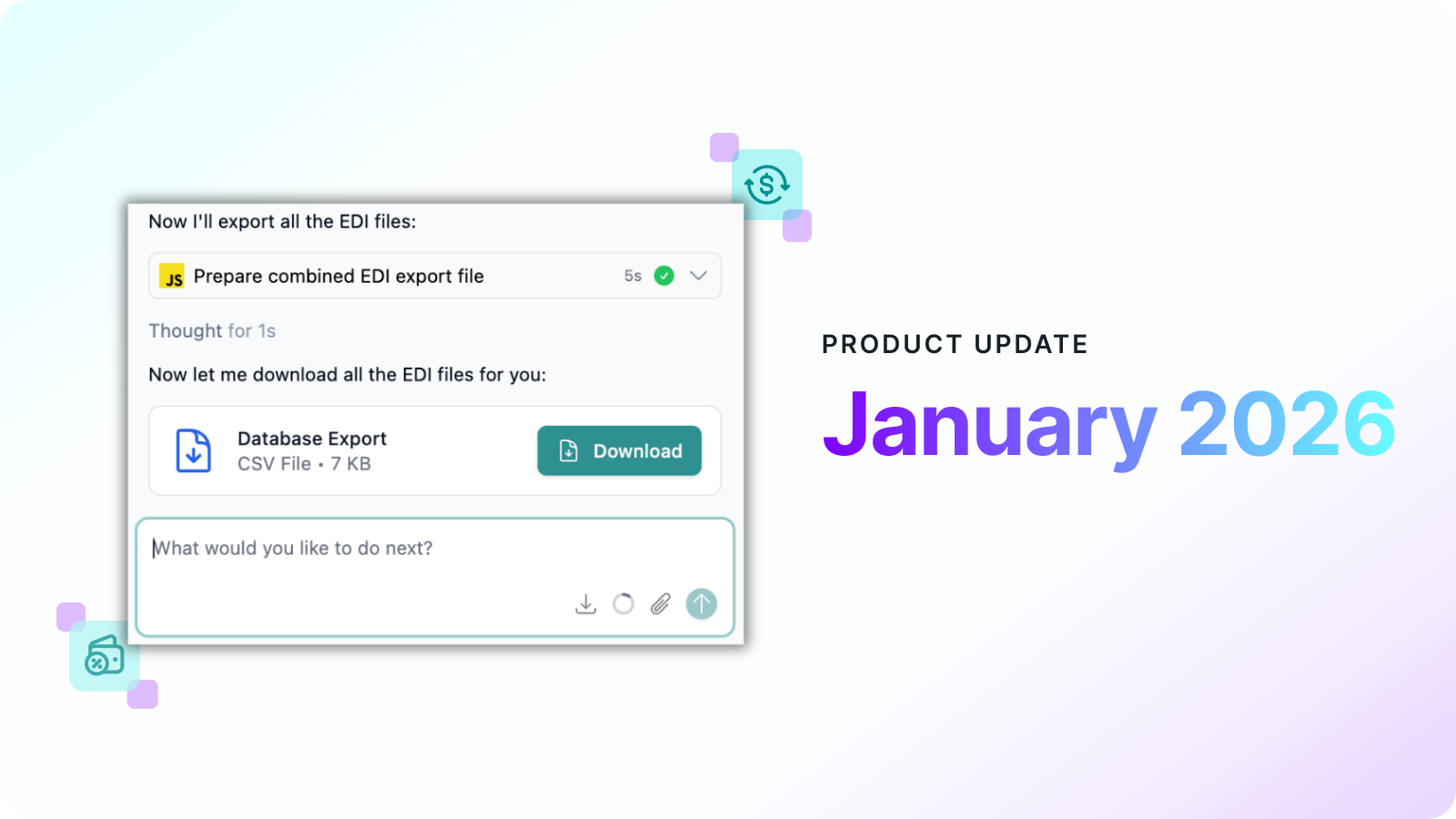
Product updates
Tonic Textual


Data privacy
Data de-identification
Data synthesis
Tonic Structural
Tonic Fabricate
Tonic Textual

Data synthesis
Data privacy
Generative AI
Tonic Structural
Tonic Fabricate
Tonic Textual

Data privacy
Healthcare
Tonic.ai editorial
Tonic Textual