The latest
De-identifying and synthesizing healthcare PDFs of patient lab reports for model training and Expert Determination
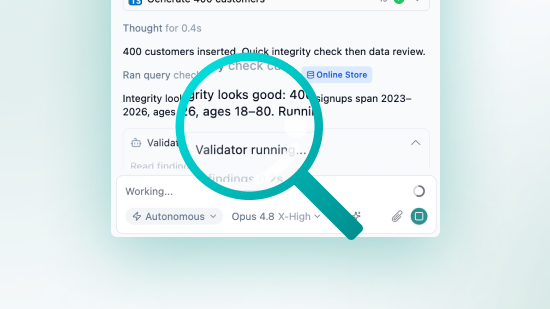
PDFs are the hardest healthcare data to de-identify. Here is how Tonic Textual identifies PHI in lab reports and synthesizes realistic replacements for Expert Determination.