
Best-in-class detection
Our best-in-class models provide out-of-the-box support for common entities, with unlimited flexibility to design your own – with support across 50+ languages, delivering the accuracy your business demands.
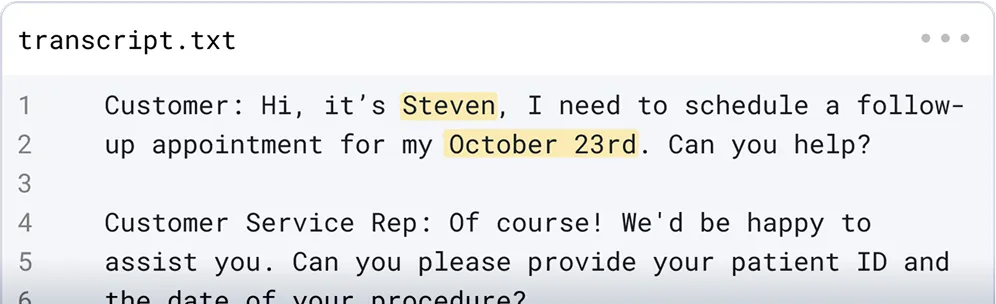
Realistic synthesis
Redact or synthesize sensitive entities consistently, without compromising quality or context, ensuring data is suitable for model training and other scenarios where data realism is critical.
Certifiable compliance
Whether it's HIPAA, GDPR, PCI, or another requirement, Tonic has established partnerships with Expert Determination providers to certify compliance for your use case.

Enterprise-grade control and collaboration
Essential security features like Role-based-access controls (RBAC) and SSO integrations to ensure the highest levels of protection across your data, and dataset sharing within the UI for easy collaboration.
Seamless detection refinement
Continuously improve Textual’s detection accuracy specific to your data and create new categories of entities beyond what’s available out of the box. Custom Entity Types lets you easily train models on your own data via a simple UI (no data science expertise required).
All your data, any format
Tonic Textual supports virtually all unstructured data formats — from free text to audio – simply feed your data into the Textual SDK or upload your files through the UI or with the Tonic SDK to quickly generate privacy-protected assets that are ready for downstream usage.

See Textual protect your data in real-time

Want to see how Textual works with one of your own documents?
Create a free account and start uploading in seconds.
Unstructured data de-identification for every use case
.svg)
In AI model training
Retain your data’s richness and preserve its statistics by replacing PII with synthetic values, to ensure optimal model training for LLM fine-tuning and custom models.

In RAG systems
Provide LLMs redacted data while optionally exposing the unredacted text to approved users. Automate pipelines to extract and normalize unstructured data into AI-ready formats.

In LLM workflows
Redact sensitive information prior to using it within LLM prompts to prevent sensitive values from ever entering the chatbot system.

In your lower environments
Accelerate data science based development with realistic test data that ensures data utility and data privacy throughout your lower environments.


Support for all your data formats
CSV
.txt
XML
HTML
JSON
.pptx
.docx
.png
.jpeg
.xls
+ more
Keep conversations private while preserving value.
Redact audio files automatically. Now that’s ••••••• awesome!
Deploy Textual on the cloud or self-hosted


Accessible where your data lives
Deploy Textual seamlessly into your own cloud environment through native integrations with cloud object stores, including S3, GCS, and Azure Blob Storage, or leverage our cloud-hosted service.



Or deploy self-hosted
For the utmost in data security and control, deploy Textual on premises using Kubernetes or Docker, in the event that your data is too sensitive to live on the cloud.








Frequently asked questions
Tonic Textual is an unstructured data redaction and synthesis solution. It's designed to safely process free-text and audio files, including support tickets, clinical notes, chat logs, and internal documents while preserving meaning and usability.
Tonic Textual uses proprietary Named Entity Recognition models to identify and transform sensitive entities like names, emails, addresses, account numbers, and domain specific identifiers. The result is privacy-safe text that still reads naturally and remains analytically useful.
Yes. It enables organizations to train and evaluate AI models on realistic text data while reducing privacy risk and improving compliance posture.
Unlike simple redaction, Tonic Textual preserves context, intent, and structure, making the data usable for analysis, search, and model development. It significantly streamlines redaction via automation and enables the detection of custom sensitive information, as well.
Customer support, data science, analytics, and machine learning teams use Tonic Textual to safely share and analyze text data without exposing PII or confidential information. Governments also use Tonic Textual to redact classified information for secure sharing.

