The latest
Synthetic data validation: How to trust data that isn't real
Synthetic data is still treated as dubious, much as AI-written code once was. Here's how synthetic data validation answers the trust question, and how Fabricate automates it.
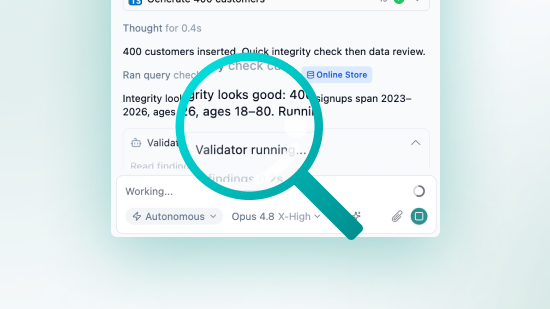
Synthetic data is still treated as dubious, much as AI-written code once was. Here's how synthetic data validation answers the trust question, and how Fabricate automates it.