
Test data generators automate the creation of datasets you can safely use in development, QA, and staging environments. Instead of copying production records—which risks regulatory violations and data breaches—or hand-crafting mock data that misses edge cases, you let a generator produce realistic data that mimics your schema, distributions, and relationships.
At a high level, two key approaches are synthetic generation from scratch and de-identification of existing data. Both approaches provide you with a secure substitute for production data in tests while preserving data utility.
Why compliance requires safe test data
Using production data in non-production environments increases privacy and regulatory risk. Test environments often lack the same access controls and audit trails as production. You could unintentionally expose real PII to developers, vendors, or third-party testers.
Common compliance concerns include:
- GDPR/CCPA violations and fees
- Unauthorized parties accessing PII
- Data breaches during QA or vendor testing
- Reputational damage
What is a test data generator?
A test data generator is a tool or service that creates representative datasets for software development and testing. Instead of manually writing SQL INSERT statements or exporting subsets of production tables, you define rules or let the generator infer schema patterns. The tool then produces data that mirrors your database structure, data distributions, and referential integrity.
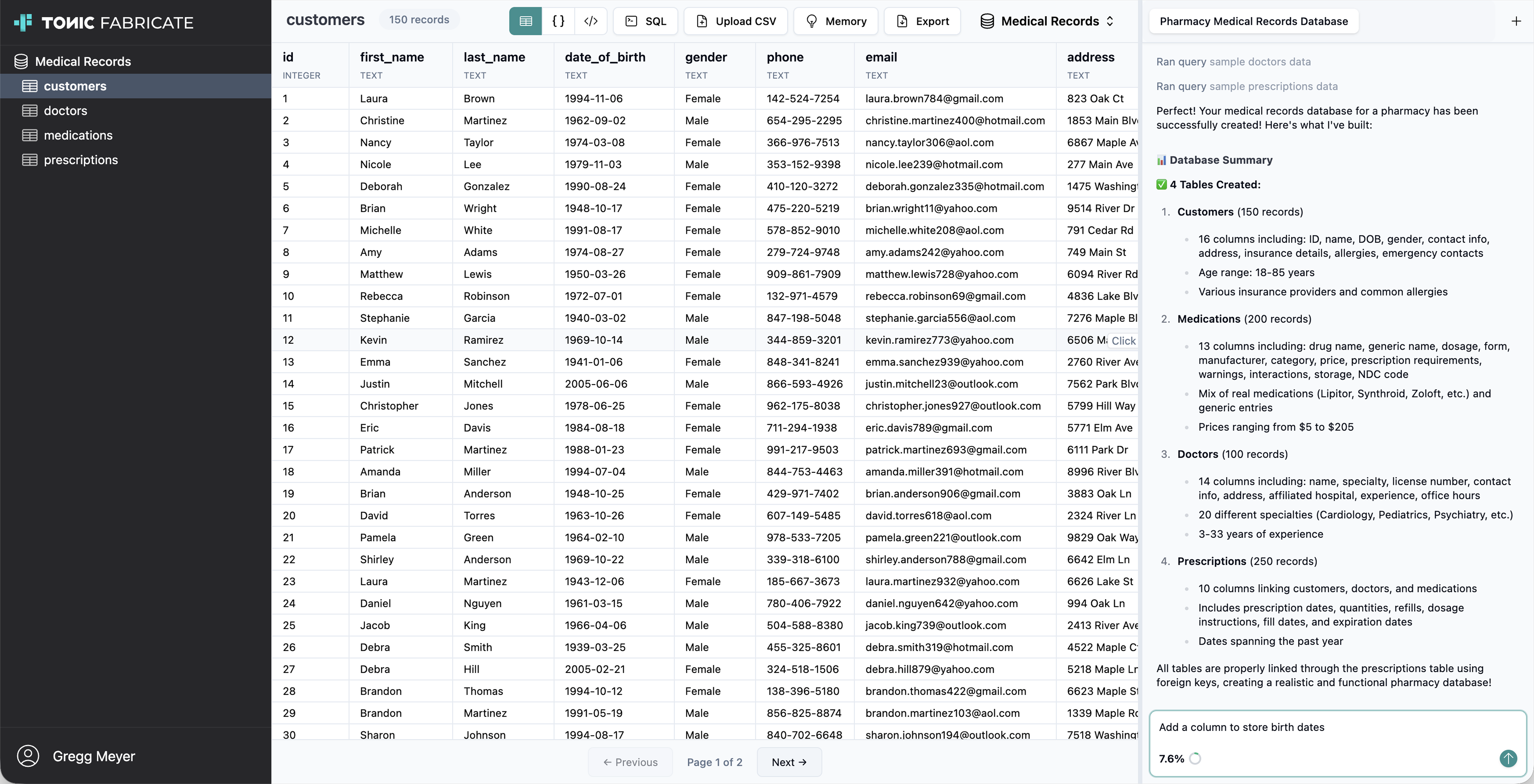
Test data generators can cover both structured and unstructured data. For structured data, they may generate names, dates, transaction records, and relationships across tables, including consistent primary and foreign keys. For unstructured text—like support tickets or free-form notes—a generator detects sensitive entities, redacts or replaces them with realistic placeholders, and can even synthesize entire documents.
How test data generators protect privacy
When you replace production data with synthetic generated or de-identified data, you reduce the chance of exposing real customer information. Generators enable you to:
- Eliminate the need to copy production data into dev or test environments—no more Jira tickets requesting sanitized exports or waiting for data teams to provision test databases.
- Preserve realism so test cases still surface bugs that only appear in production-shaped data—edge cases, null handling, referential integrity across joins.
- Speed up provisioning by generating datasets on demand, instead of requesting data exports.
- Securely collaborate with offshore or third-party teams without exposing raw PII—share test databases freely without legal review bottlenecks.
- Support data-minimization principles under the GDPR and CCPA by only creating the data you need for testing—generate just the tables, columns, and rows required for each test scenario.
- Produce audit-ready processes that trace how test data was generated or masked.
Key features of test data generators
Here are the core capabilities you should look for when evaluating a test data generator for compliance and data privacy.
Synthetic data generation (both from scratch and from existing data)
Synthetic test data generation creates new, artificial records based on your schema and sample statistics. Tonic Fabricate offers the industry-leading AI agent for synthetic data generation, the Data Agent, which generates both structured and unstructured data for you based on a schema definition, sample data, or natural language prompts. It maintains foreign-key relationships and relational integrity while generating entire tables without touching real records.
Deterministic data masking
Deterministic data masking, like that offered by Tonic Structural, replaces each sensitive value with a consistent placeholder. For example, every instance of “Alice Smith” becomes “Rebecca Johnson” across your database—in every table, every environment, every generation run.
This consistency is critical for testing workflows that depend on cross-table joins or time-series analysis where you need to track the same logical entity across multiple records. This preserves referential integrity and makes debugging easier, since the same input always yields the same output.
Format-preserving encryption
Format-preserving encryption (FPE), also offered within Tonic Structural, encrypts sensitive values like credit card numbers or phone numbers while ensuring the encrypted output maintains the same format as the input (same length and pattern). This means test logic that validates format rules, performs calculations, or checks constraints will still work correctly, while the underlying data remains secure and unreadable without the decryption key.
Maintaining referential integrity
Generated or masked data must respect foreign-key constraints so joins don’t break. A robust generator maps relationships across tables, ensuring parent-child links remain valid after transformation.
Database subsetting
Database subsetting extracts a smaller slice of your production schema-—say, 10% of rows—so you can work with a more manageable volume. The challenge: maintaining referential integrity when you subset. If you extract 10% of users, you also need their related orders, payments, and support tickets—which may reference other tables.
Tonic Structural’s patented subsetter automatically traverses foreign key relationships to pull connected records, ensuring your subset remains internally consistent and usable for testing. Combined with masking or synthesis, subsetting reduces data size and surface area while still covering critical paths.
How Tonic.ai enables secure test data generation
Tonic.ai helps you meet compliance requirements while maintaining development velocity. Tonic Structural de-identifies existing databases while preserving referential integrity, Tonic Fabricate generates hyper-realistic synthetic datasets from scratch for any domain in a matter of minutes, and Tonic Textual sanitizes PII in unstructured text fields for secure AI model training.
Integrate all three into your development workflows to automatically provision compliant, production-like test data for every build.
Ready to automate compliant test data generation? Book a demo to see how Tonic.ai helps engineering teams eliminate production data from test environments while maintaining data quality and development velocity.

A bilingual wordsmith dedicated to the art of engineering with words, Chiara has over a decade of experience supporting corporate communications at multi-national companies. She once translated for the Pope; it has more overlap with translating for developers than you might think.
.avif)



