Your data, your model: Self-serve custom entity types in Tonic Textual
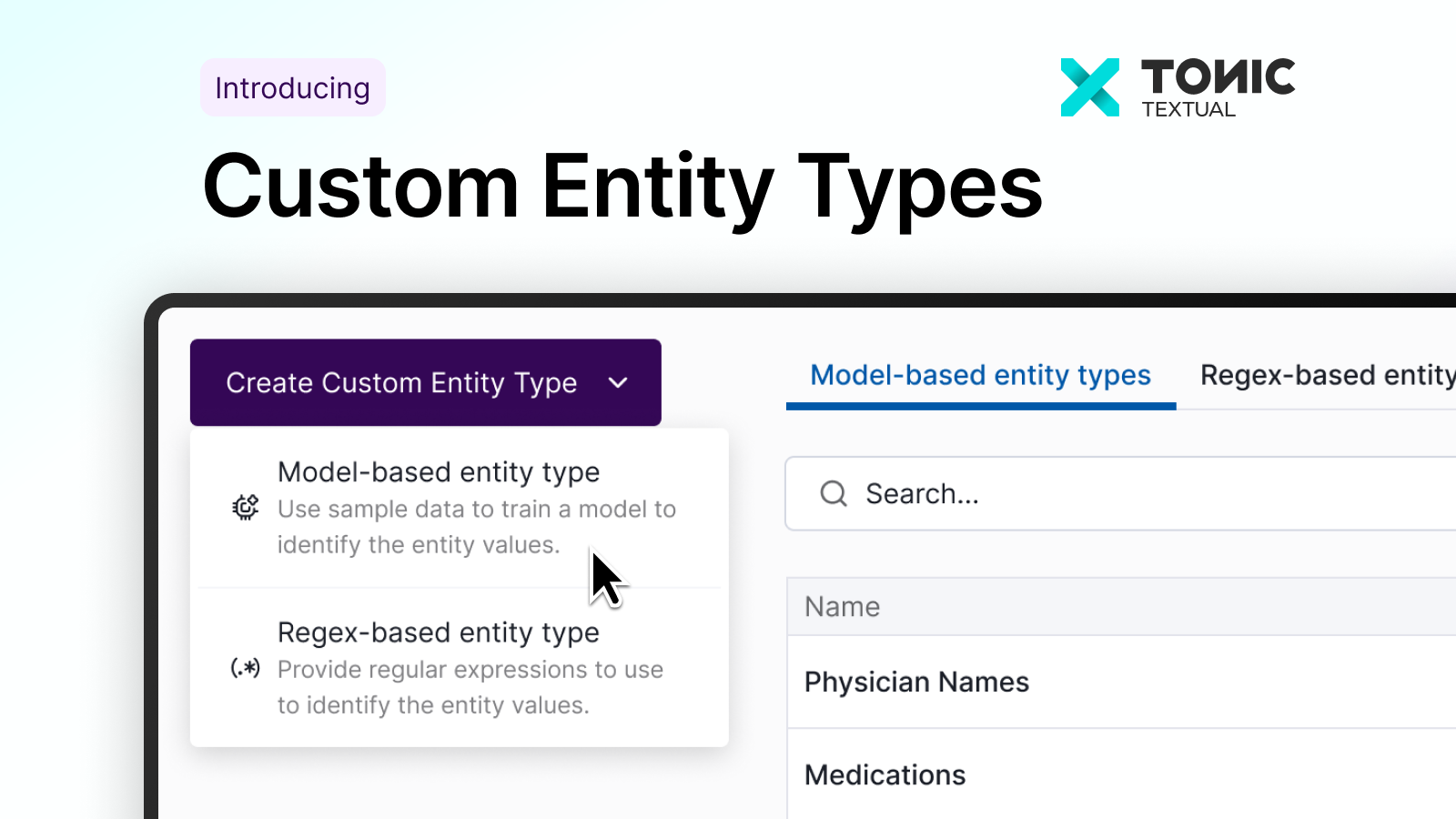
Today, we’re excited to introduce Custom Entity Types, a new capability in Tonic Textual that gives every organization the power to create their own entity detection models through a simple point-and-click interface—no specialized machine learning expertise required.
With this release, you can define and train custom entity models directly inside Textual, using your own data and infrastructure or within our secure cloud. Custom entities makes it fast and simple to add new entity types or boost the detection accuracy of existing ones.
Why we built this
Entity detection is fundamental to de-identification, compliance, and downstream AI. But every organization has unique terminology — such as physician names or biometric data in healthcare — that off-the-shelf models can’t always capture. Some terms can be captured with regular expressions, which Textual already supports, but many rely on context. That’s where custom entity types make the difference.
Custom Entity Types puts the power in your hands. This self-serve system lets your team create their own entity models trained on your data, so you can move faster and achieve higher accuracy from day one.
Make your data work for you
- Upload your data.
Start by uploading documents that include the entity you want to detect—contracts, reports, transcripts, or any text source. - AI-assisted annotation.
Textual uses a large language models to automatically identify candidate entities, distilling those results into draft annotations for your review. - Review and refine.
Use an intuitive interface to apply AI suggestions and refine your annotation guidelines to improve detection across your owned datasets. - Train your model.
With a single click, Textual trains a model on your annotations. Because the model is trained on your domain data, detection precision is exceptionally high. - Deploy securely.
Run entirely within your own infrastructure or in Tonic’s secure cloud—while retaining full ownership of your recognition models.
From upload to deployment, the process is simple: Upload → Annotate → Review → Train → Deploy.
Why It Matters
Other identification solutions typically rely on static models or service-heavy customization. Custom Entities gives your team both flexibility and independence: you own the model, the data, and the results.
By combining AI-assisted annotation with streamlined training, Textual makes entity customization something any analyst or data engineer can handle—no data science required. The result is faster time-to-value, stronger compliance alignment, and better entity detection for every AI or analytics workflow built on your text data.
Get Started
Custom Entity Types are now available to all Tonic Textual customers. If you’d like to have a conversation with a redaction expert or get your hands dirty with the product – you can schedule a demo and access a free trial of the product at the Textual product page.

Whit Moses is a go-to-market leader with over 15 years of experience helping high-growth technology companies scale. He earned his undergraduate degree from the University of Denver and holds an MBA from the USC Marshall School of Business. Whit has led sales and product marketing efforts across venture-backed startups and enterprise organizations, including pre-IPO sales at Yelp and product marketing roles at CircleCI and Astronomer. Today, he supports go-to-market strategy for Tonic Textual at Tonic.ai, helping teams safely unlock sensitive unstructured data for AI and analytics. Outside of work, Whit is an avid hiker and skier who’s always chasing his next adventure in the mountains.




