For Tonic Structural users who handle healthcare-related data, de-identifying data isn't just about company security. It's also about following the law.
In this guide, we'll provide an overview of HIPAA and its requirements to protect patient privacy and healthcare information. We'll also talk about the Safe Harbor method that HIPAA defines to enable healthcare companies to protect this information.
And for each data type involved, we’ll provide guidance on the Tonic Structural generators that you can use to transform the values that HIPAA covers.
Healthcare data and HIPAA
So to start, what is HIPAA?
The Health Insurance Portability and Accountability Act is a US law that protects patients' privacy and health information. Under HIPAA, Covered Entities (healthcare providers, healthcare clearinghouses, health plans) and their Business Associates (companies who provide services to Covered Entities) are required to take specific technical and administrative safeguards to protect the health and personal data of patients.
Organizations who handle healthcare information might want to use or share this data for a variety of legitimate purposes, because there is “potential utility of health information even when it is not individually identifiable” (see the de-identification and rationale section here). These use cases include:
- Medical research - Healthcare data can be used to conduct medical research to improve our understanding of diseases, develop new treatments, and improve patient care.
- Public health surveillance - Health data from covered entities can be used to track the spread of the flu and other viruses, identify areas with high rates of chronic diseases, and monitor the effectiveness of vaccination programs.
- Healthcare quality improvement - Providers can use data to track readmission rates, identify patients who are at high risk of complications, and develop programs to improve patient outcomes.
- Healthcare cost analysis - Companies can identify areas where costs can be reduced.
- Development of new healthcare products and services - Companies can use de-identified data to develop new diagnostic tests, personalized medicine treatments, and mobile health applications.
To share healthcare data, covered entities must remove information that identifies individuals or that provides a reasonable basis to identify an individual.
HIPAA specifically carves out the following methods to de-identify data to comply with the law:
- Expert Determination In HIPAA - Allows qualified experts to use statistical methods to de-identify patient data while ensuring a very low risk of someone being identified.
- Safe Harbor - A prescriptive method that allows organizations to remove specific individual identifiers that HHS provides.
In this guide, we'll focus on Safe Harbor.
What is Safe Harbor?
The HIPAA Safe Harbor provision creates a clear method to transform protected health information (PHI) into de-identified data. You can then use and disclose this de-identified data freely, without the limitations on PHI that HIPAA imposes.
Unlike the Expert Determination Method, the Safe Harbor Method is clearly defined, and allows you to de-identify data quickly and effectively.
Data elements that you must remove
The HIPAA Safe Harbor Method specifies the following list of specific data elements that you must remove to ensure that the information is truly de-identified:
- Names
- All geographic subdivisions smaller than a state, including street address, city, county, and zip code
- All dates (except year) related to an individual, such as birth dates and admission/discharge dates
- Telephone numbers
- Fax numbers
- Email addresses
- Social Security numbers
- Medical record numbers
- Health plan beneficiary numbers
- Account numbers
- Certificate/License numbers
- Vehicle identifiers and serial numbers
- Device identifiers and serial numbers
- Web URLs
- IP addresses
- Biometric identifiers, including finger and voice prints
- Full face photographic images and similar images
Additional Safe Harbor considerations
Though Safe Harbor removes the need for specific expert knowledge, and provides a simple list of categories that you must remove or de-identify, there are other considerations that might require additional thought.
Safe Harbor also requires the following:
The covered entity does not have actual knowledge that the information could be used alone or in combination with other information to identify an individual who is a subject of the information.
45 CFR § 164.514 (b)(2)(ii)
This means that the covered entity must ensure that it cannot re-identify the de-identified dataset using information that remains in the dataset, or in combination with other available data.
Someone with knowledge of the original data needs to answer the following questions:
- Is any data present that can be used in combination with other data in the dataset to identify individuals?
- Is any data present that can be used in combination with other data in other datasets to identify individuals? These datasets could be:
- Publicly available information
- Information that is available to other healthcare providers, covered entities, business associates, insurance companies, or research groups
- Is any of the data too granular, meaning that it could be used to make accurate inferences about who someone was, either with or without other data?
- Can any of the data be put into categories/buckets to remove this granularity and still meet the desired need of the de-identified dataset?
- Is there any other information that could be a proxy for another category of data? For example:
- A clinic name might not seem like identifying information, but its address is likely public and could be used as a proxy for a location
- Graduation date could be a proxy for age
- Are usernames just a proxy for an email address or are they functionally just a person’s first and last name?
- Are there any quasi-identifiers present in the dataset? For example, the final digits of a credit card number.
- Does the data use esoteric notation or acronyms that might appear non-identifying, but that provide additional information to those who know their meaning.
Using Tonic Structural to identify data that is subject to HIPAA Safe Harbor
You can use Structural to connect to data from a variety of commercial and open-source data stores, including:
- Relational database management systems, such as MySQL, PostgreSQL, and Db2
- Non-relational datastores, such as MongoDB and Amazon DocumentDB
- Other data sources such as Salesforce or CSV files
To see a full list of the data sources that Structural supports, visit our product docs.
The Structural sensitivity scan identifies and categorizes values that you need to protect. You can use the Privacy Hub and the Privacy Report to track the detected values and their protection status.
Structural provides generators that you can apply to protect data that falls into specific Safe Harbor categories.
Safe Harbor categories that Structural identifies specifically
Structural identifies the following Safe Harbor categories in your data:
- Names
- Locations (All geographic subdivisions smaller than a state, including street address, city, county, zip code)
- Birthdates (All dates (except year) that are related to an individual, such as birth dates and admission and discharge dates)
- Telephone numbers
- Fax numbers
- Email addresses
- Social Security numbers
- Medical record numbers
- Health plan beneficiary numbers
- Account numbers
- Certificate/License numbers
- Web URLs
- IP addresses
- Biometric identifiers, including finger and voice prints
- Full face photographic images and similar images
Structural also identifies some data types from these categories:
- Vehicle identifiers and serial numbers, specifically:
- VIN numbers
- Device identifiers and serial numbers, specifically:
- MAC addresses
- EMEI numbers
Other identifiers that Structural identifies
Structural also identifies some other types of identifiers that you should potentially de-identify, including:
- Credit card numbers
- International bank account numbers (IBAN)
- SWIFT codes for bank transfers
Using custom sensitivity rules to detect additional columns
Your data might include columns that contain data that falls under the Safe Harbor requirements, but that do not obviously belong to a sensitivity type that Structural detects automatically.
To help Structural to identify these columns, you can create custom sensitivity rules.
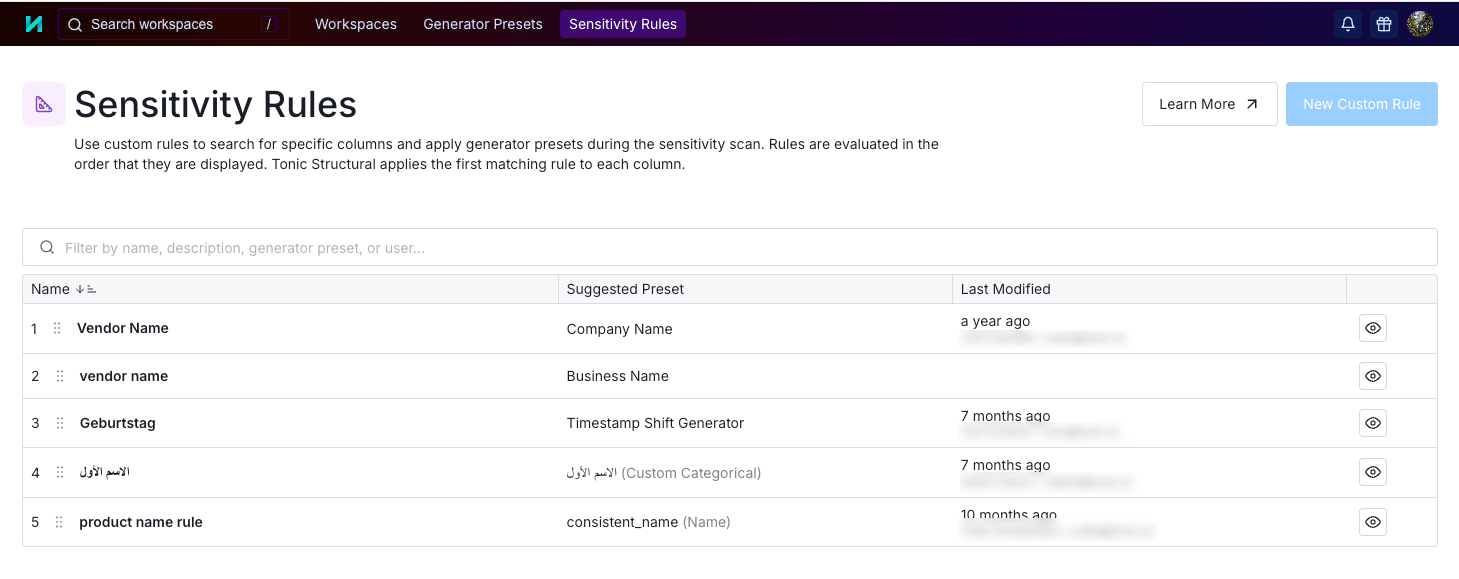
Each custom sensitivity rule checks for a combination of data type and matching column names.
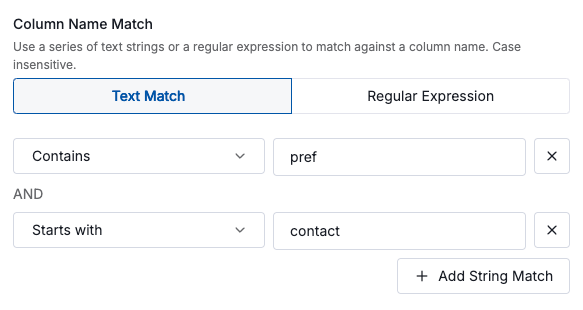
To identify the column names, you provide either:
- A set of text matching rules (starts with, contains, ends with).
- A regular expression.
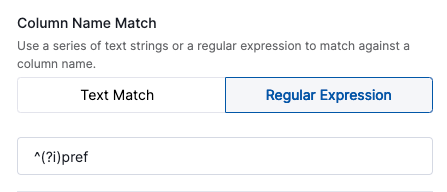
You then specify the recommended generator configuration for matching columns.
Viewing the current protection status in Privacy Hub
In Tonic Structural, Privacy Hub shows the results of the sensitivity scan and whether values are currently de-identified.
It provides a powerful way to quickly determine whether a data source contains information that needs to be de-identified in order to meet the Safe Harbor Method.
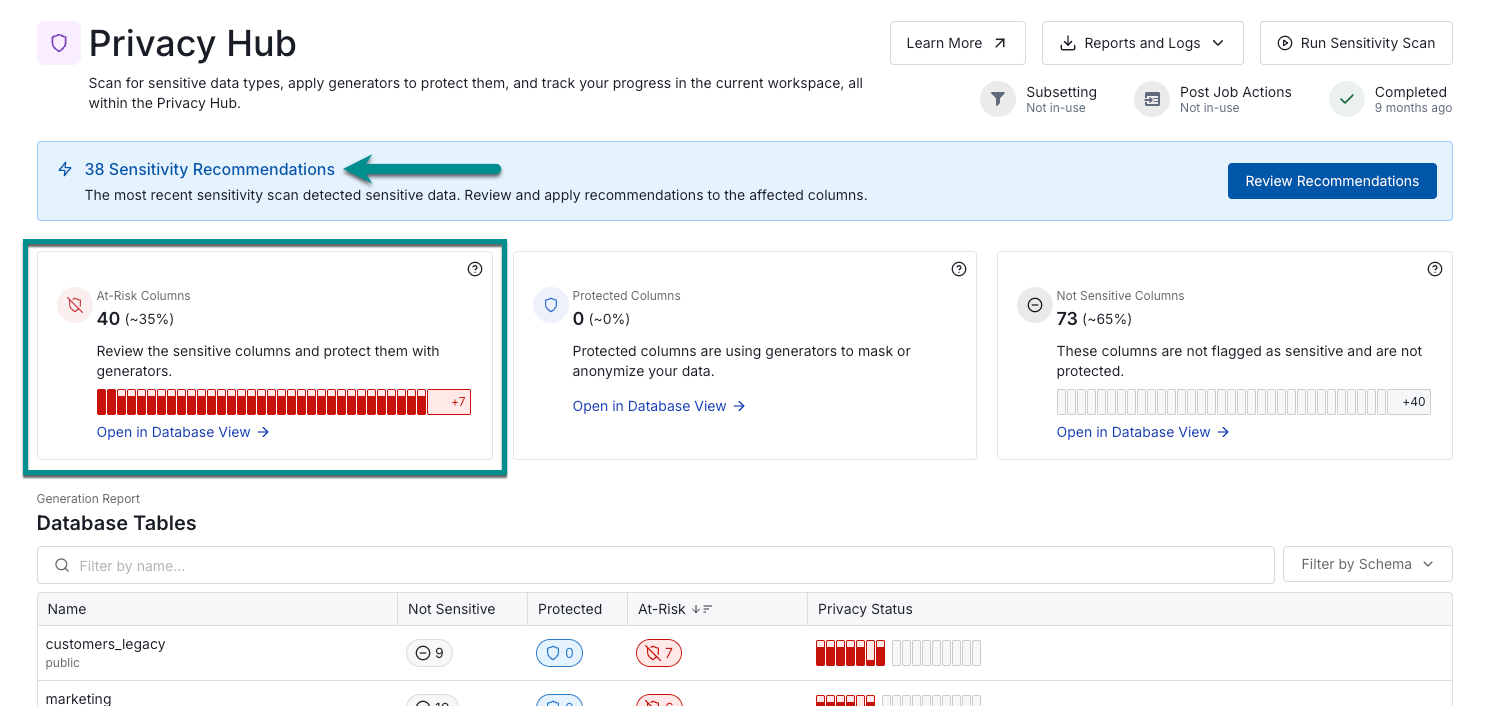
View column sensitivity and protection details Privacy Report
The downloadable Privacy Report provides a summary of your data sensitivity and protection status. It includes the types of sensitive data that Structural detected in the data.
You can use the Privacy Report:
- Before you apply generators, as a way to get started and see the scope of the work.
- After you apply generators, to help ensure data is properly de-identified.
The CSV content in the Privacy Report provides a detailed summary for each column. Here's a mockup of the report structure.

Safely de-identify PHI for software testing and development.
Accelerate healthcare innovation and AI model training with HIPAA-compliant test data.
Applying Tonic Structural generators to protect columns
Tonic Structural provides a variety of data generators that you use to replace data that needs to be de-identified, including values that the Safe Harbor Method applies to.
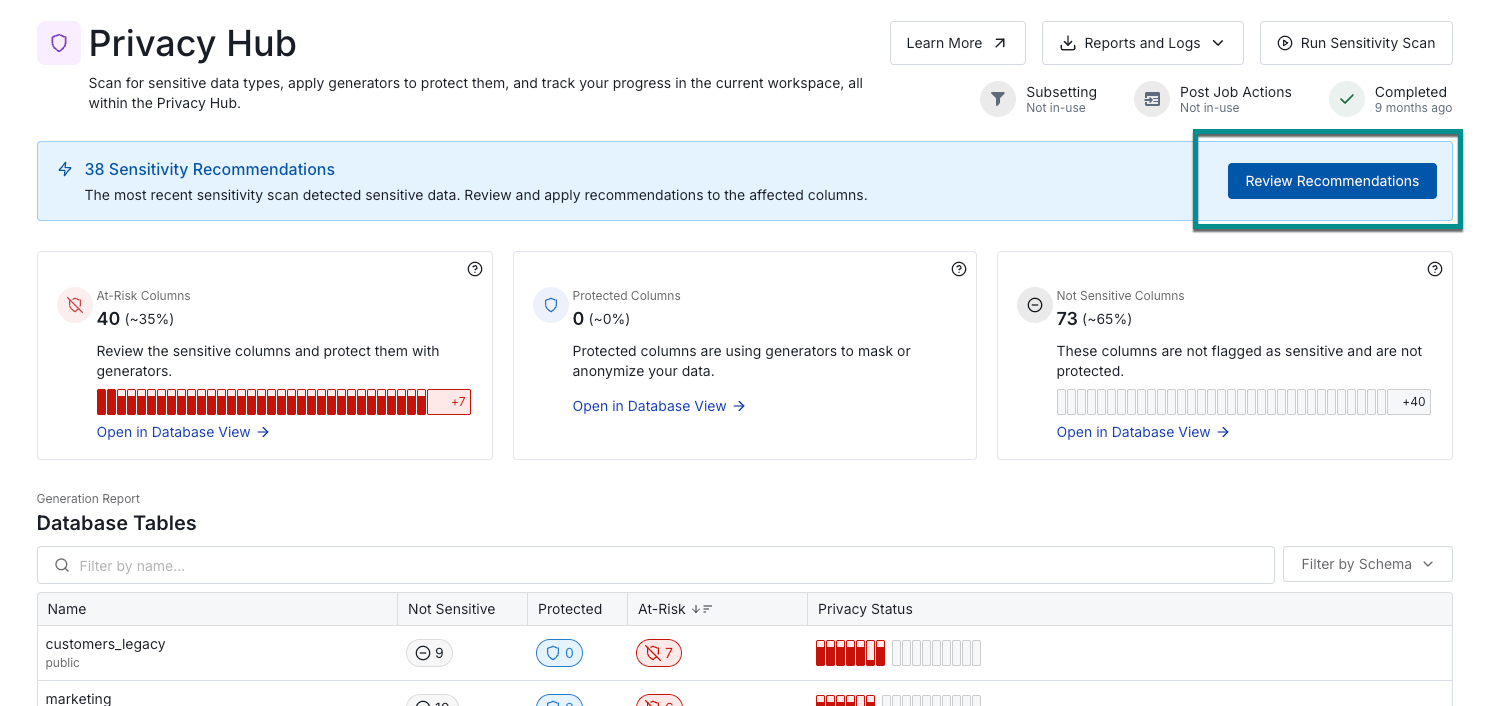
Applying recommended generators
Each column that Structural identifies has a recommended generator configuration. From the Privacy Hub, to quickly protect the identified columns, you can review and apply those recommendations.
Using the Regex Mask generator to accommodate different value formats
While the generator recommendations cover most detected values, you might sometimes need to select and configure a generator manually.
One case for manual configuration might be a column with values that have different formats.
To accommodate this, you can use the Regex Mask generator. For the Regex Mask generator, you provide regular expressions to identify the values. For each value that matches the expression, you configure generators to apply to the expression capture groups.
For example, your data contains an identifier column. The identifiers come from different systems. Sometimes the identifier is 3 uppercase letters followed by 4 numbers. For example, ABC1234. Other times the identifier is 8 numbers. For example, 98201583.
To accommodate both formats, you assign the Regex Mask generator and then provide the following regular expressions:
^([A-Z]\d{3})(\d{4})$- Matches the format that combines letters and numbers. This produces two capture groups. You could, for example, use the Constant generator to replace the letters, and the Random Integer generator to replace the numbers.(\d{8})- Matches the format that contains 8 digits. This produces a single capture group. You could, for example, use the Random Integer or Integer Key generator to mask the value.
Mapping HIPAA Safe Harbor categories to Tonic Structural generators
Let's look at how specific Structural generators apply to specific HIPAA Safe Harbor categories.
For each category, we provide an overview of why the data must be protected, and suggest Structural generators that you can use to protect it.
Names
Names, whether legal names, personal names, or nicknames, are a form of Personally Identifiable Information. Leaving PII in a dataset can be a privacy risk, because it can potentially lead to private information about a person. This might be deeply private information, such as a medical condition, or something that the individual just doesn’t want shared publicly, such as their weight or age.
Redacting names removes this key identifier. It is also required by HIPAA.
The Name generator in Structural is specifically designed to redact names by replacing real names with a random name string from a library of first and last names.
Name data types include:
- First name
- Last name
- Name
Geographic subdivisions
HIPAA allows for the retention of other demographic and medical information that, if the geographic area is not broad enough, might allow an individual to be identified.
To de-identify these geographic data types, Tonic offers a HIPAA Address generator.
Types of geographic data include:
- Address
- City
- State
- State Abbreviation
- Zip Code
- Latitude
- Longitude
All elements of dates (except year)
Birth date:
The date an individual was born.
The date could be formatted in different ways:
- MM/DD/YYYY (MDY): Places the month (MM) first, followed by the day (DD), and then the year (YYYY). Widely used in the United States, Canada, and some parts of Latin America. Example: 03/15/2024
- DD/MM/YYYY (DMY): Flips the order of day and month compared to MM/DD/YYYY. Common in many European countries, Asia, and some parts of Africa. Example: 15/03/2024
- YYYY-MM-DD (YMD): Prioritizes the year (YYYY) followed by the month (MM) and day (DD). Gaining popularity because of its international standardization and ease of sorting by date. Example: 2024-03-15
- Month name Day, Year: Spells out the month name entirely, followed by the day and year. Often used in spoken language and informal writing. Example: March 15, 2024
The Safe Harbor Method also requires that, “all ages over 89 and all elements of dates (including year) indicative of such age, except that such ages and elements may be aggregated into a single category of age 90 or older.”
Because only 4.7% of the US population is age 90 or older, it would be significantly easier to re-identify individuals based on exact age or year.
The Date Truncation generator with the Birth Date option specifically takes into account the requirements related to ages above 89.
Admission date, discharge date, date of death:
These dates could be formatted in different ways:
- MM/DD/YYYY (MDY): Places the month (MM) first, followed by the day (DD), and then the year (YYYY). Widely used in the United States, Canada, and some parts of Latin America. Example: 03/15/2024
- DD/MM/YYYY (DMY): Flips the order of day and month compared to MM/DD/YYYY. Common in many European countries, Asia, and some parts of Africa. Example: 15/03/2024
- YYYY-MM-DD (YMD): Prioritizes the year (YYYY) followed by the month (MM) and day (DD). Gaining popularity because of its international standardization and ease of sorting by date. B 2024-03-15
- Month name Day, Year: Spells out the month name entirely, followed by the day and year. Often used in spoken language and informal writing. Example: March 15, 2024
To protect these date values, you can use the Date Truncation generator to truncate to year as required by Safe Harbor.
Telephone numbers
Phone numbers can identify an individual, a household, or the individual's or household's location.
Phone numbers in the US follow a specific 10-digit format:
- Area Code (3 digits): Identifies the geographic region where the phone number is located. Precedes the local phone number.
- Local Phone Number (7 digits): Identifies a specific phone line within the area code.
For readability, US phone numbers are typically formatted in one of the following ways:
- (XXX) XXX-XXXX: Places the area code in parentheses, followed by a hyphen to separate the central office code and line number. Example: (201) 555-1234
- XXX-XXX-XXXX: This omits the parentheses around the area code. It's becoming increasingly common, especially with mobile phone use. Example: 201-555-1234
To de-identify telephone numbers, you can use the Phone generator.
Fax numbers
Fax numbers can identify an individual, a household, or the individual's or household's location.
Fax numbers in the US follow a specific 10-digit format:
- Area Code (3 digits): Identifies the geographic region where the fax number is located. Precedes the local phone number.
- Local Phone Number (7 digits): Identifies a specific fax line within the area code.
For readability, US fax numbers are typically formatted in one of the following ways:
- (XXX) XXX-XXXX: Places the area code in parentheses, followed by a hyphen to separate the central office code and line number. Example: (201) 555-1234
- XXX-XXX-XXXX: Omits the parentheses around the area code. Becoming increasingly common, especially with mobile phone use. Example: 201-555-1234
To identify faux numbers, you can use the Phone generator.
Vehicle identifiers and serial numbers, including license plate numbers
VIN and license plate information are generally available in public records and can fairly positively identify an individual.
License plate numbers vary by state, but typically contain 6 or 7 alphanumeric characters and can contain spaces or dashes after 2 or 3 characters. For example:
- 532484
- 7AAXS8
- ADL-D21
- TU 250
Vehicle identification numbers are a 17-character long international standard and follow a specific format.
- 4Y1SL65848Z411439
- 1M8GDM9AXKP042788
To de-identify a VIN or license plate number, you can use the Character Scramble or Character Substitution generator.
Device identifiers and serial numbers
These identifiers can be used to identify an individual or a family.
There are a very large range of device identifiers, including:
- Mobile phone IMEI/MEID
- MAC addresses
- Session IDs and tokens
- Advertising ID
- Device identifiers created by proprietary apps
You should confirm whether a de-identified version of this information is needed in the de-identified data set.
If they are needed, the generator needed depends on the format of the original data. In particular, whether the de-identified values need to be consistent (the same source value always results in the same destination value).
Here are some options.
For identifier types that do not need to be consistent:
For identifier types that require consistency:
Email addresses
Email addresses are used widely. You can use an email address to find large amounts of information about an individual that is available publicly on the Internet.
An email address is a unique identifier that allows you to send and receive electronic messages over the Internet. The format of an email address consists of two parts that are separated by the "at" symbol (@):
- Local-part: Comes before the "@" symbol. Identifies your mailbox within the email system. Can consist of letters, numbers, periods (.), underscores (_), and hyphens (-)
- Domain: Comes after the "@" symbol. Specifies the mail server that handles your email. Often the name of your email service provider (such as Gmail or Yahoo) or your organization's domain name (for business email addresses).
Examples:
To de-identify an email address, use one of the following generators:
Web Uniform Resource Locators (URLs)
A URL, or Uniform Resource Locator, is a web address that tells your browser where to find a specific resource on the internet.
It's like a unique identification tag for a website or document.
URLs can be used for a variety of purposes, including linking to:
- Patient records
- Patient accounts
Depending on how they are crafted, they can expose other unique identifiers (such as names, medical records numbers, account numbers) or can provide direct access to patient data.
To de-identify a URL, use the URL generator.
Social Security numbers
A Social Security number (SSN) is a unique identifier issued by the Social Security Administration. Some medical providers use SSNs to verify your identity and to bill your insurance company.
SSNs are key financial identifiers that are required for most financial transactions in the United States, including for employment.
An SSN is a nine-digit number that is broken into 3 sets of 3, 2, and 4 digits.
Examples:
- 574-73-XXXX (Issued in Alaska between 1970 and 2011)
- 313-46-XXXX (Issued in Indiana between 1955 and 2011)
To de-identify an SSN, use the SSN generator.
Internet Protocol (IP) addresses
Though they might not seem like health information or even personally identifying information, you need to de-identify IP addresses because of how they functionally work.
- IP addresses can be a fairly consistent proxy for geolocation. The accuracy is greater than the Safe Harbor criteria for “Geographic subdivisions”.
- Tracking technologies often use IP addresses to identify, among other things, unauthenticated users.
IPv4 addresses
An IPv4 address is like a unique address that identifies a device on a network. It's a unique numerical label that is written in four sets of numbers, each between 0 and 255, separated by dots. For example:
- 52.106.241.224
- 13.215.148.223
- 92.145.21.8
- 68.89.218.110
- 229.160.88.74
IPv6 addresses
IPv6 is the next generation internet protocol. It is designed to address the limitations of IPv4. Its format is a 128-bit address written as eight groups of hexadecimal digits (0-fffF), separated by colons. For example:
- 2f0c:7916:a684:c5d7:fd6c:8d39:c714:2fd2
- bf29:e2d8:ba9a:d6f6:a65e:384a:f128:6b22
- e72e:5352:9df3:0577:209d:73cd:d346:5685
- 52f4:099a:e835:4140:28fa:0535:6720:3ff2
- 0868:48ae:f8c8:b97e:2942:e93e:3c4c:482d
To de-identify an IP address, use the IP Address generator.
Medical record numbers
Medical record numbers might be shared between organizations (for example, between a doctor’s office and an insurance company, or between a doctor’s office and another doctor’s office).
Removing them is important so that other organizations who have access to these identifiers cannot easily reidentify the data.
Medical record numbers are not standardized and are different depending on the provider or entity that creates the record. The format might be:
- A sequenced integer per medical record (e.g. 75059)
- A globally unique identifier (e.g. bda7f2fd-4799-4104-84a2-5fd9fbd84150)
- Some sort of logical concatenation of information that would make finding records easier (e.g. the date and patient last name added together ‘2024-01-03-Jameson-Harris”)
This is unique to your organization. To identify them requires a review of your data structures. These might be primary or foreign keys in RDBMs systems, or other columns that are created to mask keys or make record numbers more human readable.
You should confirm that this information is needed in the de-identified data set. This information is primarily used to identify records to an individual. If that association is not needed, you might want to exclude the data.
If you do want medical record numbers in the de-identified dataset, then the generator you use depends on what your record numbers look like. To maintain the consistency that is needed for the association, the options could include:
Biometric identifiers, including finger and voice prints
Biometric identifiers can be used to positively identify an individual with extreme accuracy.
Various formats are used to store different types of biometric data in a database.
These could be chunks of binary data that are associated with different industry standards (such as ANSI/NIST-ITL for fingerprints, or ISO/IEC 19794-5 for facial recognition) or links to images, references, or models.
You should confirm whether a de-identified version of this information is needed in the de-identified data set.
If the data is stored as a string, then you might use one of the following generators:
If the biometric data is stored as a reference in another system as an identifier or a URL, then there are other options.
For identifier types that don't require consistency, you might use:
For identifier types that do require consistency, you might use:
If the identifier is a URL, then use the URL generator.
Health plan beneficiary numbers
Health plan beneficiary numbers are identifiers that are shared between organizations.
Removing them from a de-identified dataset is important so that other organizations who have access to these identifiers cannot easily reidentify the data.
Health plan beneficiary number formats vary by health plan. Different insurance providers use different formats.
If your organization uses Medicare Beneficiary Identifier (MBI) or the Health Insurance Claim Number (HICN), then these have a very strictly defined format. They are both 11-digit numbers (set of 4-3-4). An MBI would look like “1EG4-TE5-MK73.”
The MBI is completely randomly generated, while the HICN includes part of a Social Security number.
You should confirm whether this information is needed in the deidentified data set.
To preserve the overall format of the identifier with consistency, you can use the Character Substitution generator.
Full-face photographs and any comparable images
A face picture is considered identifying information because it contains unique characteristics that can be used to distinguish you from other individuals.
This data is unlikely to be stored in a database. It is more likely an identifier in a storage system or a URI of the image’s location.
You should confirm that a de-identified version of this is needed in the de-identified data set.
For identifier types that don't require consistency, you might use:
For identifier types that do require consistency, you might use:
For an identifier that is a URL, you would use the URL generator.
Account numbers
Account numbers might be shared between organizations (for example, between a doctor’s office and an insurance company, or between a doctor’s office and another doctor’s office).
Removing them is important so that other organizations who have access to these identifiers cannot easily re-identify the data.
Account numbers are not standardized. They vary depending on the provider or entity that creates the record. For example, the format might be:
- A sequenced integer (for example, 75059)
- A globally unique identifier (for example, bda7f2fd-4799-4104-84a2-5fd9fbd84150)
These values are unique to your organization. To identify them, you must review your data structures.
They might be primary or foreign keys in RDBMs systems, or other columns that were created to mask keys or to make record numbers more human readable.
You should confirm whether this information is needed in the de-identified data set.
To include account numbers in the de-identified dataset, then the generator you use depends on the record number format. To maintain the consistency that is needed for the association, you might use:
Certificate/license numbers
These numbers directly identify a specific provider or caregiver. Certificate and license numbers are not standardized. The format varies depending on the certificate and the licensing body.
You should confirm whether a de-identified version of this is needed in the de-identified data set. If so, then depending on the original format, the following options might be useful.
For identifier types that don't require consistency, you might use:
For identifier types that do require consistency, you might use:
Other unique identifiers
This category covers other identifiers that might be important but are context dependent.
Though Safe Harbor does make it much easier, faster, and less expensive to de-identify data, by giving a set of categories that should be removed or de-identified, just removing them is not enough.
The final category in the Safe Harbor method is a catchall for other identifying data. It says:
Any other unique identifying number, characteristic, or code
45 CFR § 164.514 (b)(2)(i)(R)
There are exceptions among these identifiers, outlined in paragraph (c), as follows:
(c) Implementation specifications:
Re-identification. A covered entity may assign a code or other means of record identification to allow information de-identified under this section to be re-identified by the covered entity, provided that:
(1) Derivation. The code or other means of record identification is not derived from or related to information about the individual and is not otherwise capable of being translated so as to identify the individual; and
(2) Security. The covered entity does not use or disclose the code or other means of record identification for any other purpose, and does not disclose the mechanism for re-identification.
Someone familiar with the dataset should take a step back and look at the data to determine whether any of it could identify an individual.
This could be a variety of obvious or non-obvious characteristics, such as:
- Employee ID numbers
- Social media handles
- Genetic information
- Drivers license numbers
- Passport numbers
You should confirm whether a de-identified version of this is needed in the deidentified data set, and then determine the appropriate generator to apply.
For a summary list of the available generators, go to the generator summary.
De-identifying PHI for HIPAA Safe Harbor, in summary
Organizations that manage and share healthcare data must maintain HIPAA compliance. Before they share the data, for example to use for medical research and development, they must make sure that all identifying information is de-identified.
The HIPAA Safe Harbor provision offers clear guidelines on how to transform protected health information (PHI) into de-identified data. It identifies a set of categories of information that you must de-identify.
Tonic Structural includes tools to help you to easily identify these types of values. Its sensitivity scan detects sensitive values, including the value category.
Once you identify these categories of PHI, you can apply the appropriate generator to de-identify the value. The Structural generator you choose is based on the type of value and whether the value needs to be consistent in the de-identified data.
As you configure the de-identification in Structural, you can use Privacy Hub and the Privacy Report to check your progress and verify that all of the values are de-identified.
To test out Tonic Structural on your own data, sign up for a free trial, or connect with our team to learn more.