Transform sensitive text into AI-ready data on Microsoft Fabric

We’re excited to announce Tonic Textual for Microsoft Fabric, now available in public preview to all Fabric users. Textual brings advanced entity-detection, redaction, and synthesis for unstructured text data directly into the Fabric ecosystem—empowering organizations to unlock datasets previously off limits due to privacy concerns for responsible and compliant AI/ML development.
With Tonic Textual integrated into the Fabric user experience, teams can prepare office documents, PDFs and images containing sensitive text for AI and machine learning tasks—all while protecting privacy and maintaining compliance with regulations such as HIPAA and GDPR.
Unlocking previously off-limits data
For most organizations, the biggest barrier to AI innovation isn’t compute power or LLM—it’s access to compliant data. While structured data can be easily masked or tokenized, unstructured text remains an unruly challenge for many organizations. The variance across unstructured text is infinite, with personal information often embedded in nuance and context that’s hard to detect with traditional tools.
Manually de-identifying large volumes of sensitive data is an overwhelming task, and often achievable. Each document must be reviewed line by line to locate private information, making in-house solutions both unsustainable and error-prone—especially as data volumes grow and compliance requirements evolve.
Tonic Textual for Microsoft Fabric eliminates that burden. By combining Fabric’s lake-centric architecture and governance with Tonic’s AI-driven de-identification engine, users can easily and automatically identify and protect sensitive entities—such as names, dates, and medical or financial identifiers—without moving data out of Fabric.
The result: privacy-preserving datasets that are immediately ready for downstream workflows including model training, generative AI workloads and AI Agents.
Unlocking AI in regulated environments
Consider a healthcare organization developing an AI assistant to help clinicians summarize patient case notes. These records contain valuable medical insights—but also a significant amount of personally identifiable information (PII) and protected health information (PHI).
Using Tonic Textual in Microsoft Fabric, the organization can safely process and transform its unstructured EHR data directly in OneLake. Textual automatically detects and anonymizes sensitive entities while maintaining the integrity of clinical language—ensuring data utility for downstream analytics, ML training and AI.
This enables data scientists and clinicians and business users to collaborate confidently, knowing that sensitive data is protected and would never leave their secure Fabric environment.
Getting started: De-identifying Text Data in Fabric
Example: How to prepare sensitive text data for AI in just a few clicks.
Step 1: Add the Tonic Textual Workload
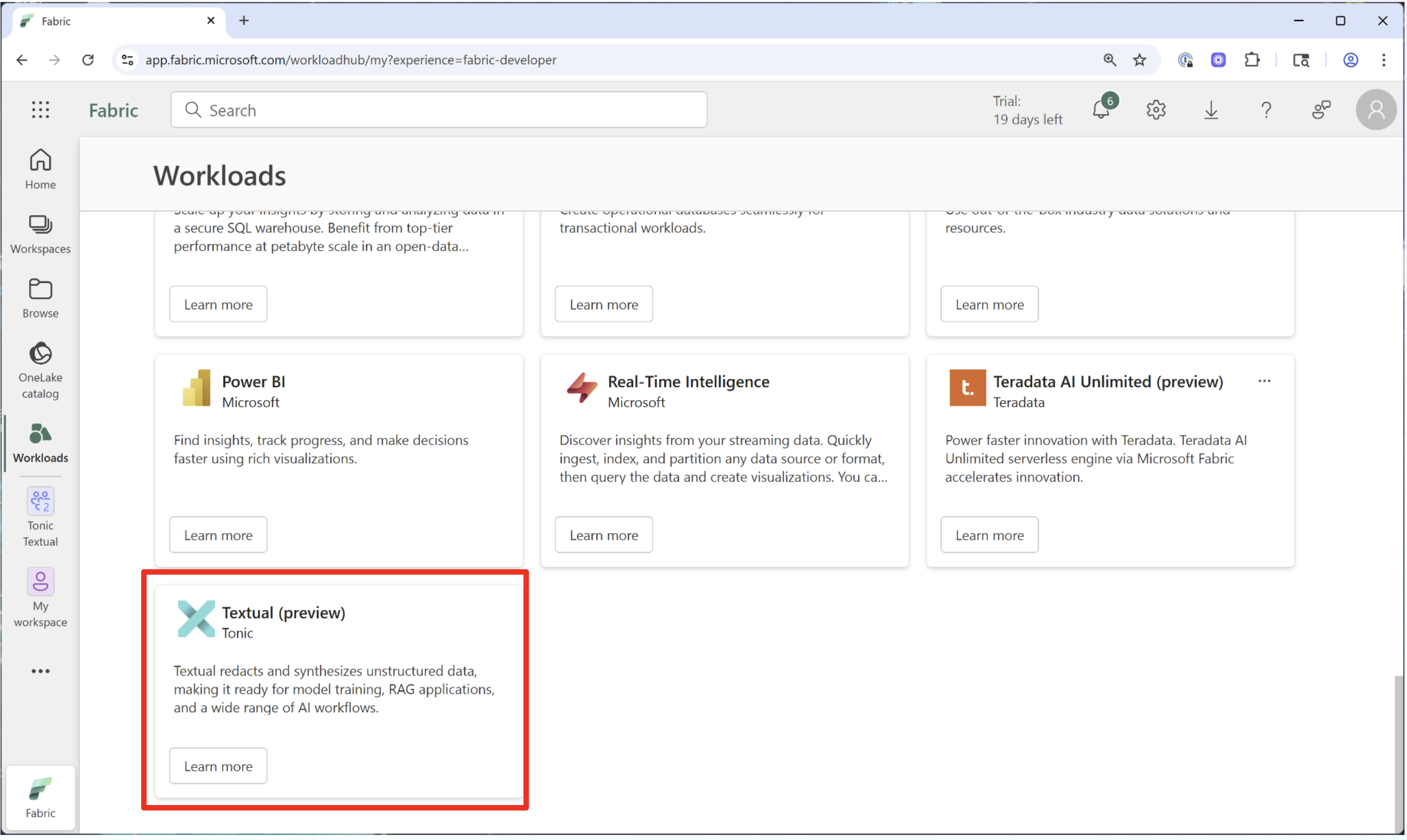
From your Fabric console, navigate to Workloads and select the Tonic Textual workload to add it to your workspace. Learn more about adding workloads. Once added, you will have access to the Textual UI directly from your Microsoft Fabric console.
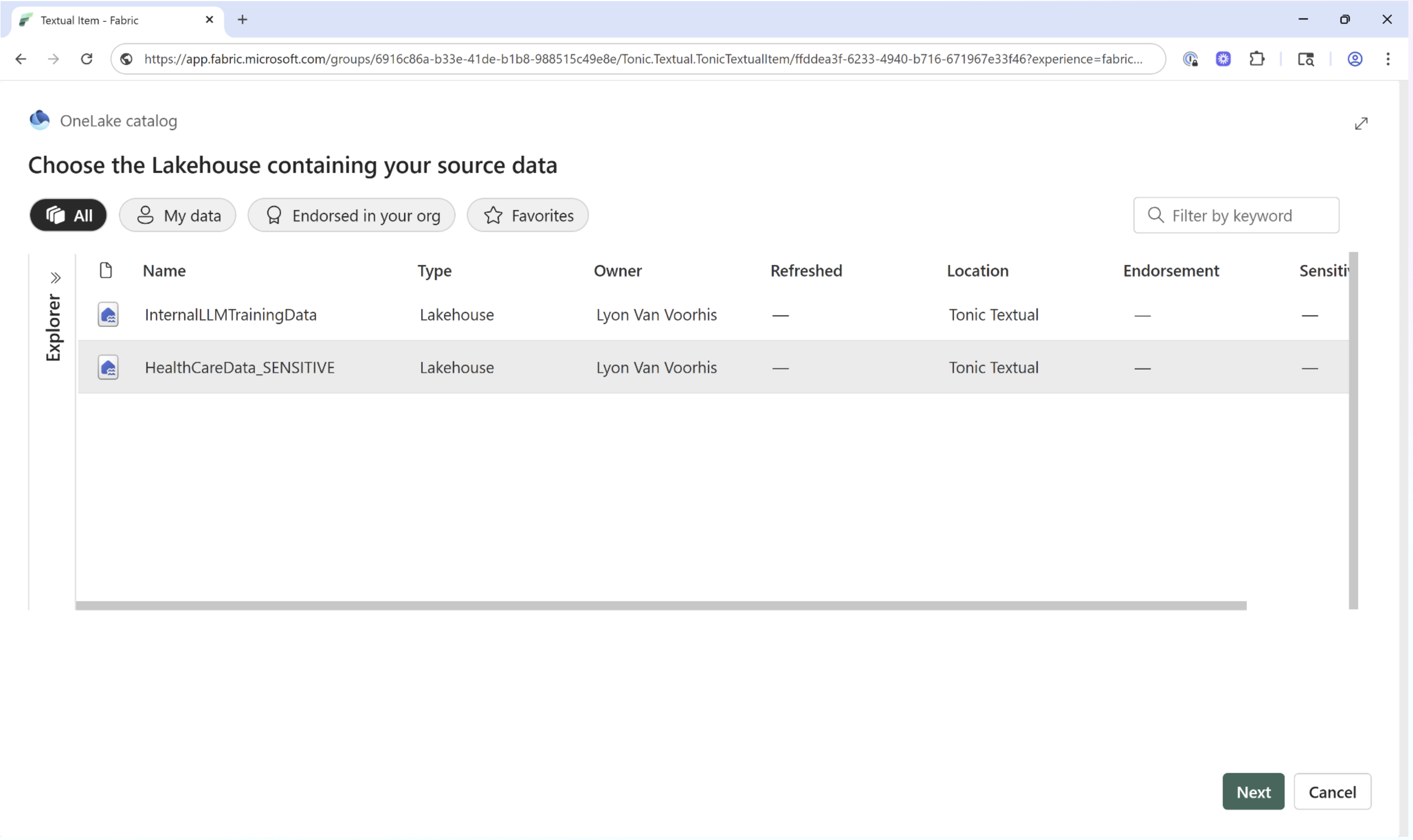
Step 2: Configure your input and output location
Step 3: Create a Tonic Textual Item
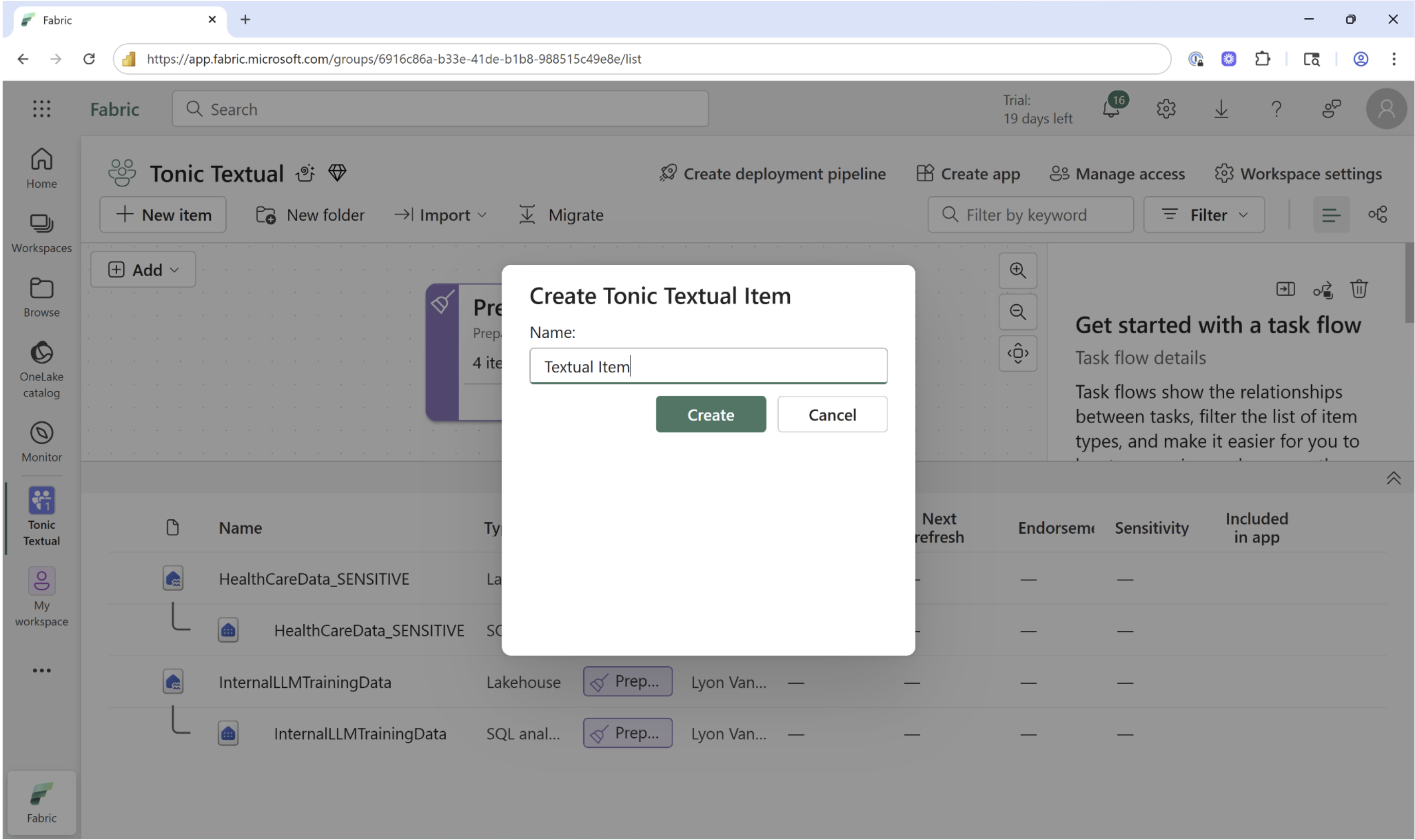
To use Textual, first open your workspace and click New Item. Select the Tonic Textual from the list of available items.
Next, choose the OneLake Lakehouse containing the files you want to process. Next, choose a target folder where sanitized files will be saved..
Step 4: Scan your files for sensitive text
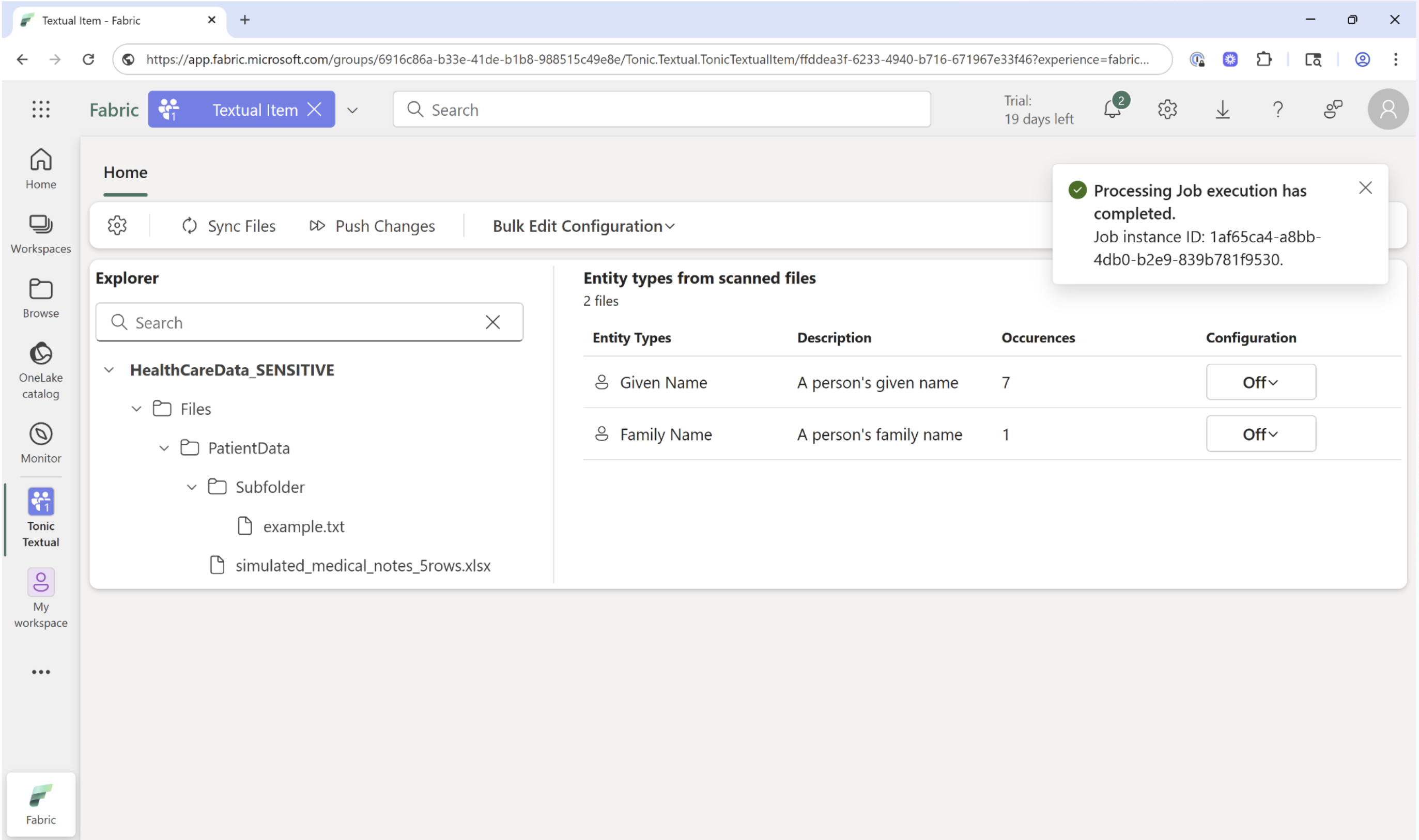
Select the specific files or entire folders of files containing sensitive data you want to sanitize. In this example, we have scanned two files from the folder ‘Patient Data’. On the right hand side you can see the status of the job indicating multiple detections of first and last names.
Step 5: Configure your de-identification preference

After reviewing the initial analysis of sensitive text identified within your documents, you need to decide what action to take. You can choose a combination of redactions or synthesis (replace with a true-to-life substitute – i.e “John” becomes “William”), or to leave certain entities untouched. In this example, we are using the “Bulk Edit” to automatically redact all of the sensitive entities.
Step 6: Access your sanitized files

Once the de-identification job is complete, your sanitized files are accessible in the destination folder that you created in Step 2. These files are essentially replicas of the originals, but with redacted or replaced entities based upon your de-identification strategy. Your original files remain un-altered in their source Lakehouse – the sanitized versions are ready for downstream use. With this data unlocked, you can use Azure AI Foundry service to build AI agents in Azure Copilot Studio, enable search using Azure AI Search or train your own ML models using Azure Machine Learning.
Why It Matters
Bringing Tonic Textual into Microsoft Fabric makes it easier than ever for organizations to responsibly harness the power of their unstructured data.
- Compliance-first by design: Sensitive data stays within your governed Fabric environment.
- Seamless integration: Textual workflows run natively in Fabric, eliminating external transfers or manual preprocessing.
- Accelerated AI innovation: Unlock text data for model training, retrieval-augmented generation (RAG) workflows, and other downstream development with privacy built in.
- Enterprise scalability: Designed for Fabric’s performance and governance standards, ensuring consistency across projects and teams.
With this integration, Microsoft and Tonic.ai are helping organizations move from blocked to AI-ready, at scale.
Get Started Today
Tonic Textual for Microsoft Fabric is now available in Public Preview.
Explore the integration, attend upcoming sessions at Microsoft Ignite, and enable Textual directly in your Fabric workspace.
Visit https://www.tonic.ai/partners/microsoft/fabric to learn more about this integration.

Whit Moses is a go-to-market leader with over 15 years of experience helping high-growth technology companies scale. He earned his undergraduate degree from the University of Denver and holds an MBA from the USC Marshall School of Business. Whit has led sales and product marketing efforts across venture-backed startups and enterprise organizations, including pre-IPO sales at Yelp and product marketing roles at CircleCI and Astronomer. Today, he supports go-to-market strategy for Tonic Textual at Tonic.ai, helping teams safely unlock sensitive unstructured data for AI and analytics. Outside of work, Whit is an avid hiker and skier who’s always chasing his next adventure in the mountains.





