Synthetic data is artificially generated information that is used to mirror the patterns and statistical properties of real datasets without the risk of exposing real individuals. It can be created entirely from scratch or generated using existing data as a model, making it statistically useful while helping preserve privacy.
For artificial intelligence applications, this approach can be transformative. Data synthesis for AI allows data scientists to train and test AI models in a safe, scalable way to optimize performance without using sensitive or restricted datasets. When it comes to uses like healthcare diagnostics, financial fraud detection, or SaaS customer analytics, data synthesis for AI makes it possible for organizations to create accurate models while still maintaining privacy and compliance.
Types of synthetic data used in AI
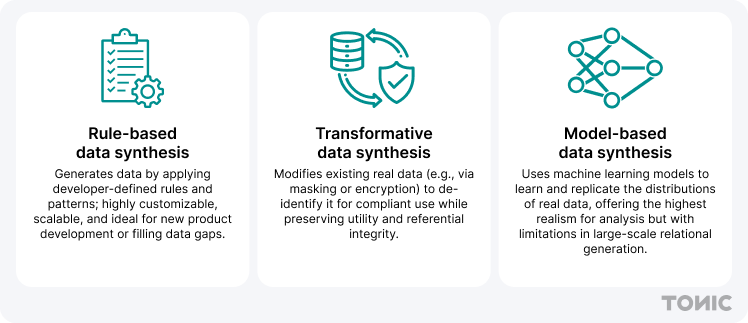
Data synthesis for AI varies depending on specific needs. Three main high-level approaches include rule-based, transformative, and model-based synthesis:
- Rule-based synthesis creates artificial data from predefined rules and formats, such as making fake customer records from realistic but non-identifiable values. It’s scalable, predictable, and perfect for testing how an AI model handles structured inputs.
- Transformative synthesis starts with real data but alters it through masking, shuffling, or perturbation, all of which protect privacy while keeping patterns intact. This approach is quite common in highly regulated industries, as AI engineers and data scientists need training data that is representative of reality without the risk of exposing actual details.
- Model-based synthesis is the most advanced method of generating synthetic data, as it relies on generative models––such as GANs or VAEs––to produce new datasets that mirror real-world complexity. This technique is particularly well-suited for research and data analytics use cases, which require the highest degree of data fidelity.
How is synthetic data used for AI?
Synthetic data offers unique advantages as a data augmentation approach. Unlike anonymization, which offers a one-to-one transformation of real to synthetic datasets, data synthesis for AI can also spin up new information. This technique creates datasets with the diversity and scale needed for training and deploying AI models without relying on sensitive real-world data.
Synthetic data can be used across multiple use cases: to safely train and fine-tune machine learning models, protect PII, fill gaps where real data is scarce, or ensure coverage of rare but important scenarios. These capabilities help accelerate development cycles, reduce compliance risks, and strengthen overall AI model performance.
And these applications span industries: healthcare organizations can test diagnostic tools without exposing patient data; financial institutions can simulate fraud scenarios at scale; and SaaS companies can stress-test products before release. In each case, synthetic data generation helps AI systems perform better, faster, and more responsibly.
Training and fine-tuning machine learning models
Synthetic data can be used to train and fine-tune LLM models without depending on sensitive or proprietary datasets. Development teams can generate large volumes of diverse examples to either pre-train models or fine-tune them for specific tasks, for example, boosting the rate of experimentation and improving performance overall.
Enhance privacy by protecting personally Identifiable Information (PII)
Data synthesis for AI offers the same benefits of data de-identification in replacing personally identifiable information with representative values, to remove PII from test and training datasets. When synthetic records are generated from scratch, meanwhile, no sensitive information is ever involved. This makes synthetic data an effective way to safeguard PII in industries like healthcare and finance, where compliance with privacy regulations is critically important.
Augmenting datasets where existing data is lacking
In some use cases, the real-world data needed to train a model is scarce, expensive to collect, or possibly doesn’t exist yet. By leveraging data synthesis for AI, teams can fill those gaps, ensuring artificial intelligence systems have enough variety to learn from.
Ensuring edge case coverage
Similarly, AI models often struggle with rare but important scenarios, such as handling unusual medical conditions or fraudulent transactions. Synthetic data lets data scientists simulate these edge cases to train models and make them more resilient in high-stakes environments.
Reducing bias in your data
Real-world datasets can reflect systemic bias, leading to unfair or skewed results. Using synthetic data generation, teams can rebalance training data, ensuring AI systems are exposed to a wider variety of examples and produce more equitable outcomes.
Synthesize high-fidelity data for AI model training.
Unblock AI innovation with high-fidelity synthetic data that mirrors your data's context and relationships.
How Tonic.ai supports data synthesis for AI applications
Tonic.ai provides privacy-first platforms that generate synthetic data tailored for building, training, and testing AI models. Each solution is designed to maintain data utility and trainability while eliminating the risks of exposing sensitive information:
Tonic Textual
Tonic Textual creates high-quality synthetic unstructured datasets that mimic the structure and semantics of real records. This is especially useful for training natural language processing (NLP) models in customer service, healthcare, or finance––all areas where sensitive free-text and audio data can’t be used directly.
Tonic Structural
Tonic Structural synthesizes relational databases while preserving the statistical integrity of the original. Data scientists can safely use this synthetic data to test and optimize AI applications without risking exposure of PII or financial records.
Tonic Fabricate
Tonic Fabricate generates synthetic data from scratch, both as fully-formed relational databases and as unstructured data within those databases. It offers the flexibility to customize and scale data to fill the gaps in model training datasets, without ever requiring access to real-world data.
Try Tonic.ai for a privacy-first approach
Data synthesis for AI allows organizations to maximize innovation without compromising privacy. By generating artificial yet realistic datasets, teams can safely train and refine AI systems, protect PII, and fill in the gaps where real-world data is either nonexistent, scarce, or too sensitive to access.
Using techniques like rule-based, transformative, or model-based data synthesis, synthetic data enables AI models to perform better across industries—from healthcare to finance to cybersecurity. The key is ensuring privacy is built in from the start so that models can immediately deliver value without risking compliance.
Tonic.ai provides the tools to make this possible, empowering organizations to generate synthetic datasets that maintain utility while safeguarding sensitive information.
Ready to see how Tonic.ai can support your data journey? Book a demo today and discover how a privacy-first approach can fuel your next generation of AI.

.avif)



