Synthetic data isn't real, which makes a skeptic's question fair: how do you know it's any good? Synthetic data validation is the process of confirming that generated data is realistic, representative, and fit for its intended use. In other words, that it holds up when you put it to work.
Quality is the foundation of trust here. Validation is how synthetic data reaches a high enough quality bar to earn that trust, and with agentic AI, that validation step no longer has to be manual. This piece covers two things: why synthetic data has to earn your trust, and how agentic validation now does that work for you.
Why synthetic data still gets the side-eye
The objection to synthetic data isn't that it's fake. It's that you can't easily tell whether it's good. You generate a dataset, it looks plausible — schema's right, values are reasonable — but you're still left with the one question that matters: will it behave like production data, or just resemble it?
That uncertainty, not the artificiality, is what stalls adoption. A dataset you can't vouch for is a dataset you won't use.
And vouching for it has been hard. The answer to how to validate synthetic data has long been: by hand. You compare distributions, run discriminator tests, eyeball samples, and pull in someone who knows the domain to say whether it looks right. Qualtrics' overview of validation methods captures this widely-accepted definition: it’s an almost entirely manual, analyst-driven process.
To date, judging synthetic data quality has been subjective and expert-dependent. Researchers who studied the practice found that practitioners often can't even agree on what "good" means, and that most validation still happens by eye. When quality is a matter of opinion, doubt is the rational default.
Layer in the fact that synthetic data can now be AI-generated, and that doubt is amplified by hallucinations and the autonomous nature of AI data generation. So how can AI-generated synthetic data like that spun up by Tonic Fabricate earn our trust? Luckily, we’ve got a playbook in how we code.
How AI-written code reached quality and earned trust
In the early days, code from a model was something you treated with suspicion, and rightly so. It was unreliable. You couldn't trust a line of it without reading every line of it. The early tools were really just a better autocomplete: handy for finishing a function you'd already started, useless for anything you wouldn't have written yourself.
Then the models got good enough to act as a kind of pair programmer. They could draft a whole feature from a description. But they still needed constant steering: you'd point, they'd write, you'd correct, they'd try again. The work went faster, but the human was still the only thing standing between the output and a bug in production.
What changed the game wasn't only smarter models. It was review. The current generation of coding systems runs as multiple agents in a loop: one explores the problem, another writes the code, another reviews it, another tests it, and they hand work back and forth until it holds up. That feedback loop is what finally allowed AI-written code to clear a genuinely high quality bar and pass human review with only minor corrections.
And that — not raw model intelligence — is what earned it trust. The lesson generalizes: AI output becomes trustworthy when a critic holds it to a standard, not when the generator simply gets smarter.
The maker and the critic: Why a second, impartial reviewer works
There's a reason code review has always involved a second person, and it has nothing to do with AI. The person who makes a thing can't be an impartial judge of it. You know what you meant to build, so your eyes slide right over the spot where what you built doesn't match. A reviewer carries none of that baggage. They see the work as it is, and they catch what you can't.
This is the maker and the critic, one of the oldest quality mechanisms we have. Writers have editors. Buildings have inspectors. Code has reviewers.
AI-generated synthetic data has been missing its critic. The dynamic that legitimized AI-written code transfers directly: pair the thing that generates the data with a separate, impartial reviewer whose only job is to judge whether the output is any good. That's what turns "probably fine" into confirmed quality.
And confirmed quality is exactly what earns trust, the thing synthetic data has been striving to achieve.
How synthetic data validation works in Tonic Fabricate
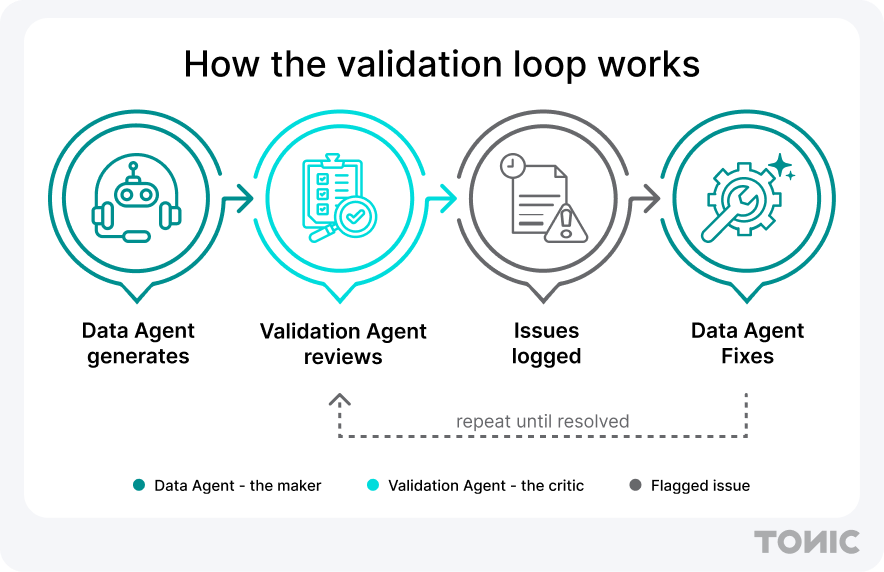
This is the idea behind the Validation Agent in Tonic Fabricate, our synthetic data product. Fabricate is an agentic synthetic data generation platform: you describe the data you want in plain language, and the Data Agent builds it — a relational database, JSON, unstructured files, whatever the job calls for.
The Data Agent is the maker. The Validation Agent is the critic. Enable it, and it reviews what the Data Agent produced, checking it against what you actually asked for. When it finds a problem, whether that’s as simple as a column in the wrong format or as complex as a patient journey that isn’t medically plausible, it logs the issue. This isn’t just a spot check. The Validation Agent sees the forest in addition to the trees. The Data Agent fixes what was flagged, and the cycle repeats until nothing’s left to fix.
And it works the same no matter where the data comes from: whether the Data Agent is filling an empty schema or modeling new data on a live database you've connected to Fabricate, the Validation Agent reviews the output for accuracy and catches the faults.
The payoff is quality you can trust even when your prompt was vague. You don't have to specify everything perfectly up front, because the loop catches and corrects what the first pass got wrong.
Validate code, data, or both
Validation in Fabricate has two toggles: Review Data and Review Code. You can toggle on both, or just one.
Review Data inspects the generated output itself: the actual rows, files, and values. Review Code inspects the generation logic before it runs. Here's the part people misread: reviewing code doesn't judge whether the code is clean or fast. Nobody cares if the script is elegant. It checks one thing: whether the code would produce realistic data. It critiques the recipe, not the cooking.
Which you want comes down to scale:
The rule of thumb: on small jobs, review the data; on large jobs, review the code too, so you catch a flawed approach before it generates a mountain of unusable rows.
Why the Validation Agent stays an impartial outsider
Here's something we got wrong at first. It seemed obvious the Validation Agent would do better if we handed it everything the Data Agent knew: the full context, the hints about what to watch for, the assumptions behind the generation. More information, better review. Right?
Wrong. Fed all that context, the Validation Agent got worse. It inherited the Data Agent's blind spots. Primed with the maker's assumptions, it stopped seeing the work as it was and started seeing it the way the maker intended, exactly the failure a critic exists to prevent.
So we keep it an outsider. The Validation Agent doesn't get the Data Agent's reasoning. Its job is singular: look at the output, judge whether it's realistic synthetic data, and ignore everything else. The maker makes. The critic, knowing nothing, judges. And thanks to the fact that it knows nothing, it catches more.
Pairing validation with Autonomous mode, and what it costs
None of this is free, and I won't pretend otherwise. Running two agents in a loop — generate, review, fix, review again — costs more than a single pass. In practice, expect validation to raise the cost of a job by roughly two to four times.
That sounds steep until you price in the alternative. What the loop replaces isn't a cheaper machine; it's your time. Reaching the same synthetic data quality by hand means hours of an engineer comparing distributions, spotting the off column, re-steering the generator, and checking again. Engineering time is the most expensive line on the sheet. Against it, a 2–4× compute cost to take the human out of the loop is a bargain.
That's why validation pairs naturally with Autonomous mode, where the Data Agent plans and runs the entire job without stopping to ask you anything. Turn on validation, start the job, walk away. You come back to data that's already been held to a standard, needing little more than a glance before you can put it to use.
Takeaway: Synthetic data you can trust, because its quality is confirmed
So can you trust synthetic data generated by AI? Yes, for the same reason you can trust AI-written-and-reviewed code. Not on faith, but because something held it to a standard and confirmed it cleared the bar. And synthetic data can be that good: a model trained on nothing but synthetic data from Fabricate has matched and beaten models that learned from real data. Validation is how you reach that level dependably, instead of hoping a single pass got it right. The critic that does the confirming is the Validation Agent, and it's in Fabricate today.
Curious to see it in action? Let’s chat.

Mark Brocato is a software developer and entrepreneur best known as the founder of Mockaroo, one of the world’s leading synthetic data generators, launched in 2014. The idea for Mockaroo came while Mark was watching QA engineers struggle to test complex life science workflows at a startup called BioFortis, inspiring him to make realistic test data easier for everyone. With over two decades in software development, he’s built tools for developers at Sencha, Layer0, and beyond. In 2024, Mark launched Fabricate, the AI-powered synthetic data platform that was acquired by Tonic.ai in 2025, where Mark continues to lead its development. A Ruby, JavaScript, and Rust developer, he divides his time between Sparta, New Jersey, and Tallinn, Estonia.




