Simulated environments for reinforcement learning
Build realistic simulated environments to train and evaluate AI agents, populated with production-modeled data, personas, tasks, and live APIs, at any scale.

.svg)
Put simulated environments to work

Populate RL environments with domain-specific data
Generate realistic, domain-specific datasets at scale to populate any RL environment. Connect to your existing databases to model synthetic data on real-world structure, or describe a new domain from scratch. Either way, Fabricate builds the data and API layer to match.

Create evals and benchmarks for AI models
Build high-quality evaluation environments with known-correct answers and controllable difficulty levels. Synthetic data gives you structured metadata to programmatically construct tasks, from simple lookups to multi-hop reasoning chains, with verifiable ground truth.

Train autonomous customer support agents
Teach your agents to navigate realistic inboxes, ticketing systems, and knowledge bases. Synthetic data lets you simulate the full range of customer interactions, from routine requests to edge-case escalations, so your agent handles real-world complexity before it ever touches production systems.

Build AI agents for enterprise operations
Train agents to work across enterprise tool stacks — email, calendar, CRM, project management — where multi-step tasks require reasoning across interconnected systems. Model synthetic data on your production systems to mirror the messy reality of professional workflows.
Why teams choose Tonic.ai for simluated environments

Unlimited scale without data collection bottlenecks
Real-world datasets are scarce, expensive, and slow to collect. Fabricate generates training data at any scale, modeled on your production data or built from scratch, so your RL pipeline is never blocked by data availability.

Controllable complexity for better training outcomes
Real corpora give you what they have, not what you need. Synthetic data lets you control task difficulty, ensure coverage of edge cases, and structure the metadata that makes verifiable, multi-hop evaluation possible.

No dependency on scarce or sensitive real-world data
The only large public email corpus is 25 years old. Most enterprise domains have no open dataset at all. Synthetic data eliminates your dependency on hard-to-find corpora and sidesteps privacy and compliance constraints entirely.

Fabricate-generated synthetic data outperformed frontier models on real-world tasks, with zero real data in the training set.

From a seed prompt to a complete simulated world
Describe or connect to your world
Start with a natural-language prompt describing the domain you want to simulate, or connect to an existing database to inherit real-world schema, relationships, and distributions.
Generate structured data
Fabricate builds out the full world: relational databases with org structures, user profiles, timelines, and interconnected events, all logically consistent and referentially intact.
Generate realistic content
From the structured foundation, Fabricate produces the unstructured artifacts your agent actually sees — emails, messages, documents, tickets — each written in a distinct voice and grounded in the underlying data.
Stand up mock APIs
Fabricate's interactive mock APIs give your agent something to act against. Your RL environment gets tool endpoints that behave like real systems — search, read, update — backed by the synthetic data underneath.
Construct tasks and train
Use the structured metadata layer to programmatically build tasks at varying difficulty levels, generate verifiable question-answer pairs, and feed them into your RL training loop.
Simulation solutions built for RL environments
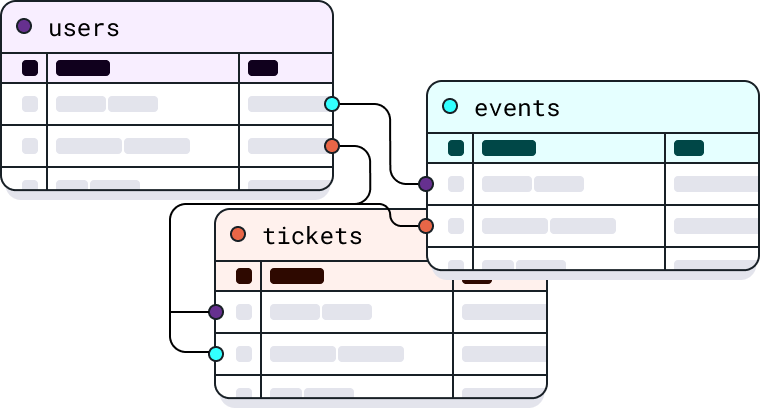
Schema-aware relational data generation
Generate entire relational databases with org charts, user profiles, event timelines, and cross-references that maintain full referential integrity across tables. This structured metadata is what makes it possible to construct RL tasks with known ground truth and controllable difficulty.
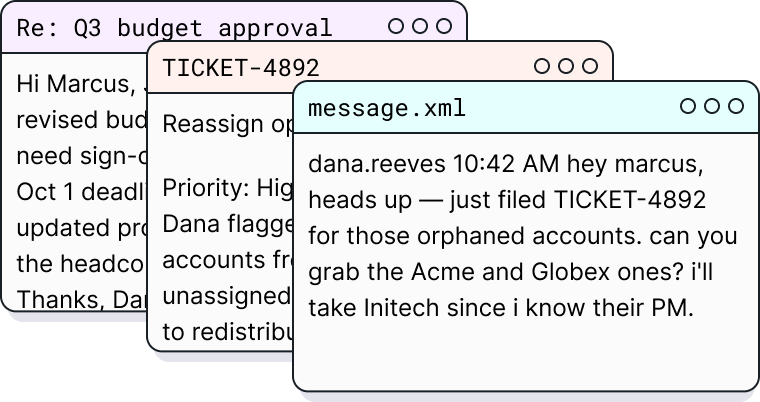
Character-consistent free-text generation
Produce emails, messages, tickets, and documents that are grounded in the underlying data and written in distinct, consistent character voices. Each piece of content reflects the personality, seniority, and communication style defined in the structured layer, not generic placeholder text.
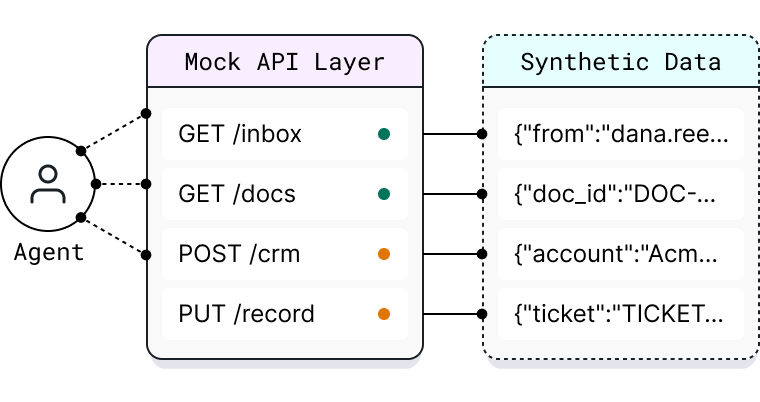
Live APIs for serving agents
Stand up tool endpoints that your agent can call during training: search an inbox, read a document, query a CRM, update a record. Mock APIs are backed by your synthetic dataset and return realistic responses, giving your environment the state and action space it needs.
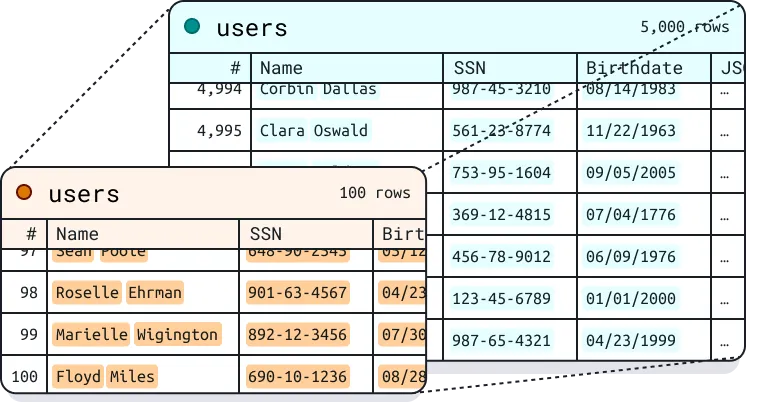
Entity detection and data de-identification
Already have real-world data you want to use? Tonic Textual detects and replaces sensitive entities in your existing text (names, emails, account numbers, medical records, etc.) so you can safely feed real data into RL pipelines without privacy risk.

Live Connect to model synthetic data on production databases
Connect Fabricate directly to your production database and use its real structure, patterns, and distributions as the blueprint for synthetic generation. Live Connect means your synthetic data inherits the complexity of your real data — schema relationships, value distributions, edge cases — without exposing any of the sensitive information within it.

Data augmentation from existing sources
Don't have enough data? Combine Textual's de-identification of your existing data with Fabricate's generation capabilities to augment what you have and fill the gaps, expanding your dataset's volume, variety, and complexity.
Start building the simulated worlds your agents need.
Model environments on your production systems or build new worlds from scratch, at any scale.
Common questions
Synthetic data for RL is artificially generated data that populates the environments where AI agents train. Instead of relying on scarce, expensive real-world datasets, teams use synthetic data to create realistic scenarios — complete with structured databases, free-text content, and interactive tool endpoints — that agents learn from through trial and reward.
Real-world datasets are expensive to collect, limited in scope, and often contain sensitive information that creates compliance risk. Synthetic data eliminates these constraints while giving you control over task difficulty, edge-case coverage, and data volume. Research has demonstrated that models trained entirely on synthetic data can match or exceed the performance of models trained on real data.
Tonic.ai provides the data layer. You use Tonic Fabricate to generate the realistic, structured, and unstructured datasets that populate your RL environments, along with mock APIs that give agents something to interact with. If you have existing production data, Fabricate's Live Connect feature can model your synthetic data directly on your real database's structure and patterns.
Tonic.ai's tool-agnostic architecture supports environments that mirror both enterprise workflows (email, calendar, CRM, ticketing) and consumer applications (social, messaging, shopping). You define the domain, and Fabricate generates the data and API layer to match.
Yes. If you have a production database, Fabricate's Live Connect feature lets you connect directly to it and generate synthetic data modeled on your real schema, patterns, and distributions — without exposing sensitive information. Tonic Textual can also de-identify sensitive entities in your existing free-text data. From there, Fabricate can augment that data with additional synthetic records to increase volume, variety, and complexity.
Fabricate generates logically consistent, relationally coherent data — not random filler. In a published benchmark, a model fine-tuned exclusively on Fabricate-generated synthetic data outperformed frontier models on real-world email tasks it had never seen. The structured metadata layer ensures that every piece of generated content is grounded in an underlying data model.
A mock API is an interactive endpoint that mimics the behavior of a real software tool — like searching an inbox or updating a CRM record. In an RL environment, mock APIs give agents actions to take and observations to receive. Fabricate's mock APIs are backed by your synthetic dataset, so responses are contextually realistic.


