Unlock new possibilities with synthetic datasets

Preserving clinical meaning
De-identify PHI without destroying the medical nuance your models depend on. Context-aware detection preserves timelines, relationships, and other variables so that your data never loses value.

Operating at enterprise scale
Process billions of clinical notes, transcripts, and documents reliably. No brittle scripts. No throughput bottlenecks.

Unlock stalled AI initiatives
Move AI projects out of compliance limbo with de-identified text that is safe for training, evaluation, and internal experimentation.
.svg)
Enable safe data sharing
Prepare high-fidelity datasets for partners, research, and analytics while maintaining document structure and auditability.
Built for clinical data at scale
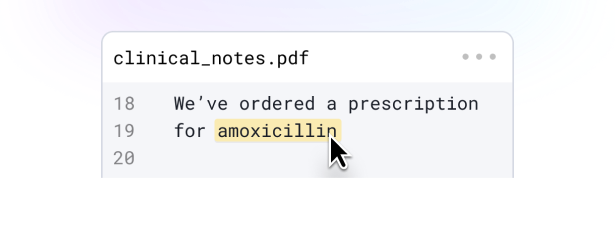
Context-aware PHI detection for clinical text
Accurately identify and transform PHI across physician notes, discharge summaries, ambient transcripts, PDFs, and scanned documents while preserving clinical intent.

High-throughput processing at LLM scale
Architected to handle massive text volumes with consistent performance, enabling continuous AI pipelines instead of batch-based experiments.

Preservation of document structure
Maintain formatting, tables, references, and layout across complex file types so downstream users retain full clinical context.

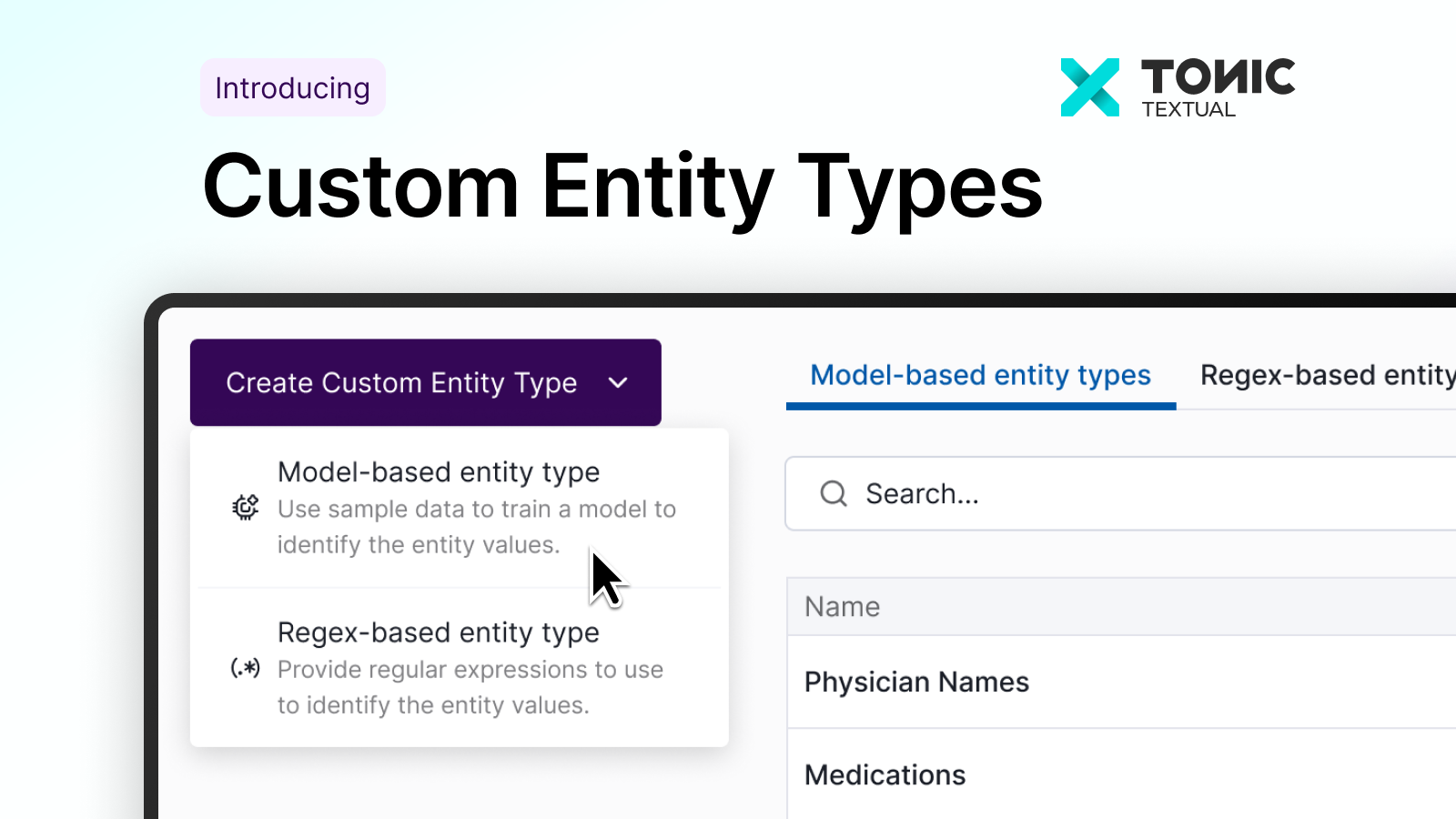
Self-serve model tuning for clinical and organizational context
Train and deploy custom entity types to capture the identifiers that matter most to your organization, from specialty-specific clinical terminology to internal IDs, provider names, and workflow artifacts.
Audit-ready workflows built for HIPAA compliance
Streamline the path to compliance with workflows tested to meet regulatory requirements. Tonic.ai partners with qualified expert determination providers to ensure that accreditation is never a blocker.

Explore Tonic Textual's full capabilities
Best-in-class detection models and enterprise-grade control and collaboration features power the accuracy and security you need.




Let's chat.