Introducing the Unstructured Data Catalog: From unknown text to usable data
Most organizations are sitting on massive volumes of unstructured text data without a clear understanding of what’s actually inside it. Documents, notes, transcripts, and records pile up across systems, holding valuable context for AI development — but remain largely siloed — often sitting stagnant with no strategic vision for how they can create value.
Within that data are insights teams want to use: signals for model training, evaluation, search, and automation. At the same time, it often contains sensitive information that makes teams hesitant to touch it at all.
Tonic Textual changes that by automatically detecting sensitive entities in unstructured text and transforming them through redaction or realistic synthetic replacement, preserving critical context while making data safe for AI and analytics. Instead of choosing between risk and progress, teams can finally understand what’s in their data and how it can be used.
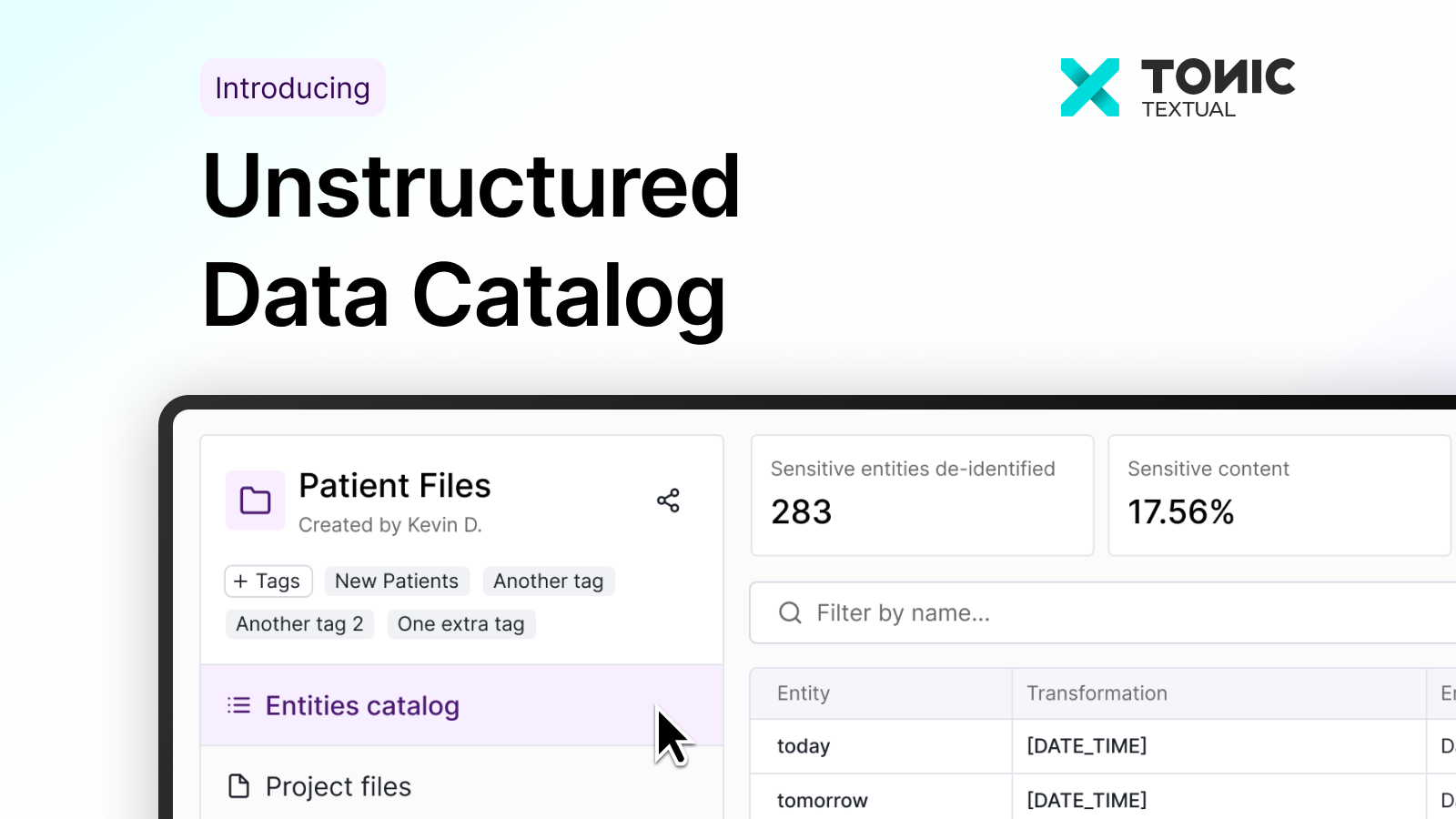
Today, we’re excited to announce the general availability of the Unstructured Data Catalog in Textual, giving teams a centralized, searchable view into their unstructured text data so they can move faster with confidence.
Turning unstructured text into a system of record
These new capabilities centralize and organize text data across thousands of documents, giving teams a single, searchable view of sensitive information and how it appears throughout their organization.
Instead of manually reviewing files or relying on fragmented metadata, teams can now see:
- What sensitive entities exist across their documents
- Where those entities appear
- How they’ve been transformed or handled
- The context in which they occur
This turns unstructured text into an indexable, queryable system of record — unlocking faster discovery, safer AI development, and stronger governance.
A central dashboard for sensitive text data
textAt the core of this new interface is a centralized dashboard that organizes unstructured data by meaningful metadata, including detected entity type, associated files, detection confidence, transformations applied, and surrounding context.
Teams can filter and search across millions of words in seconds to pinpoint:
- Documents containing specific names, diagnoses, locations, or identifiers
- Patterns or concentrations of sensitive information
- Datasets appropriate for downstream AI or analytics workflows
This creates a single source of truth for understanding what sensitive data exists across the organization and how it’s being used.
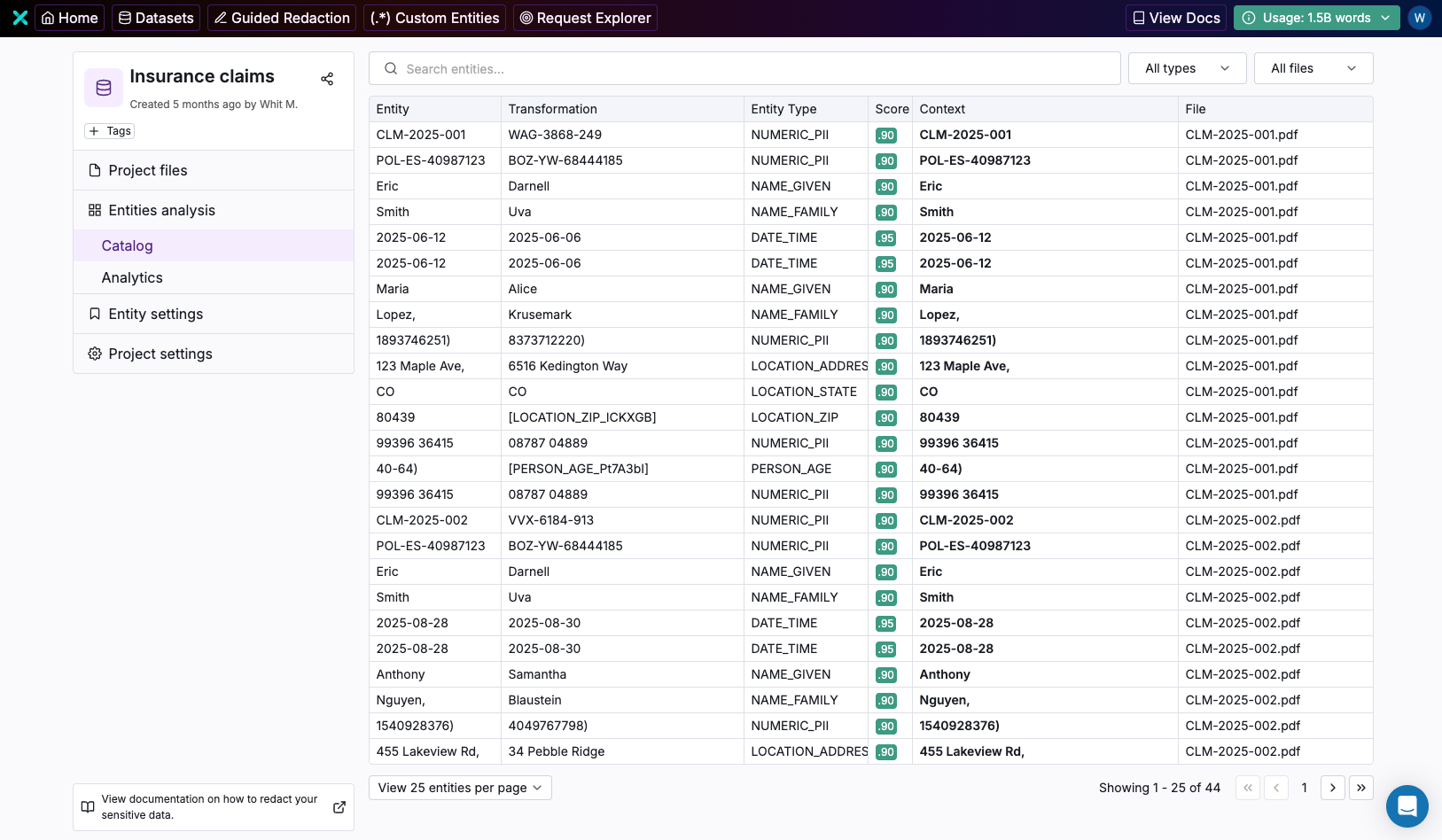
Ask questions, get answers with intelligent search
The Textual UI now includes an LLM-powered search assistant that allows users to query their data using natural language.
Instead of writing complex queries or scanning documents manually, teams can ask questions like:
- What percentage of these medical discharge notes contain a diagnosis for influenza where the patient age is less than 7?
- How many of my documents contain the family name ‘Wilson’ and city ‘Detroit’?
- What transformation is used for the state location ‘CO’ in the file ‘CLM-2025-001’?
The search assistant analyzes data across the catalog and returns contextual, actionable answers in seconds — making large-scale text analysis accessible to technical, engineering, and compliance teams alike.
Built for AI teams, engineers, and compliance leaders
Once teams can see what sensitive text data they have and understand how it’s being used, entirely new workflows become possible. The Unstructured Data Catalog unlocks use cases across AI development, engineering planning, compliance, and enterprise discovery.
AI and machine learning development
Teams can identify documents with the right context for training or evaluation, validate that data is privacy-safe, and export relevant subsets with confidence.
Engineering visibility and planning
Engineering leaders gain a clear view into what unstructured data the organization holds, how it’s being transformed, and where new AI initiatives may be possible — while flagging sensitive data risks early.
Compliance, legal, and risk management
Compliance teams can discover where sensitive information lives, audit how it’s used or transformed, and support internal reviews, regulatory inquiries, or access controls with confidence.
Enterprise search and knowledge discovery
Organizations can locate critical documents, surface trends across large text collections, and dramatically reduce the time spent searching for information.
Making sensitive data discoverable — and governable
As organizations scale their use of AI, understanding unstructured data is no longer optional. Sensitive information must be discoverable, auditable, and sanitized for downstream use — without sacrificing privacy, compliance, or the valuable context contained within.
The Unstructured Data Catalog gives teams the visibility they need to move faster and safer with text data.
The Unstructured Data Catalog is available now in Tonic Textual. To learn more or see it in action, request a demo.

Whit Moses is a go-to-market leader with over 15 years of experience helping high-growth technology companies scale. He earned his undergraduate degree from the University of Denver and holds an MBA from the USC Marshall School of Business. Whit has led sales and product marketing efforts across venture-backed startups and enterprise organizations, including pre-IPO sales at Yelp and product marketing roles at CircleCI and Astronomer. Today, he supports go-to-market strategy for Tonic Textual at Tonic.ai, helping teams safely unlock sensitive unstructured data for AI and analytics. Outside of work, Whit is an avid hiker and skier who’s always chasing his next adventure in the mountains.