
Yesterday, OpenAI released Privacy Filter (OPF), an open-source 1.5B-parameter mixture-of-experts model for detecting PII in text. It's a thoughtful release: Apache 2.0 licensed, small enough to run in a browser or on a laptop, and state-of-the-art on PII-Masking-300k, a widely used synthetic PII benchmark.
We spend our time at Tonic.ai thinking about exactly this problem, and we were curious how the model performs on the kind of data our customers actually send through our redaction pipelines: electronic-health-record notes, call-center transcripts, loan contracts, and general web scrapes. We also wanted to understand why it behaves the way it does, and what it would take to close any gaps we found.
This post covers three things:
- A head-to-head benchmark of OPF against our production redactor, Tonic Textual, on four real-data test groups.
- A brief mechanistic look at where OPF succeeds and where it falls short.
- A fine-tuning experiment to understand how much labeled data is needed to make OPF competitive on specific domains.
The short version: OPF is an excellent base model for PII detection, in roughly the way BERT or RoBERTa are excellent base models for token classification. What it is not — at least out of the box — is a drop-in replacement for a mature, domain-tuned redactor. The difference between the two is training data, and a lot of it.
PII detection benchmark: OpenAI Privacy Filter vs. Tonic Textual on real data
OPF exposes 8 PII categories: account_number, private_address, private_email, private_person, private_phone, private_url, private_date, and secret. Textual emits 26 finer-grained labels. For a clean comparison we project both systems into OPF's 8-class space and evaluate at the token level, which sidesteps the boundary mismatches that come from Textual splitting "123 Main St, Boston, MA 02115" into address / city / state / zip while OPF treats it as one private_address.
Our test corpus is 500+ documents across four domains:
- Web crawl — assorted scraped pages with embedded PII
- EHR notes — de-identified-format clinical records
- Legal documents — contracts and NDA disclosures
- ASR transcripts — call-center call recordings
On the six labels both systems actively predict (person, address, email, phone, date, account_number):
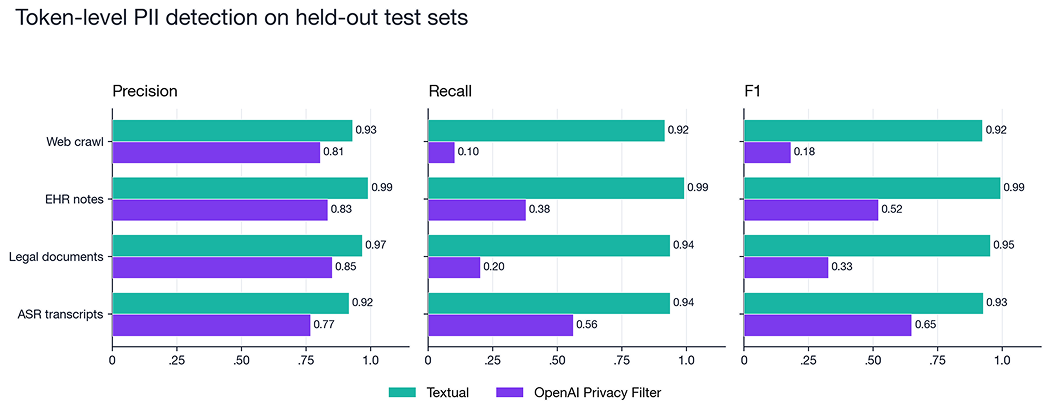
Textual leads on F1 across every group — 0.92–0.99 vs 0.18–0.65. What jumps out when you break it apart: precision is broadly comparable (0.77–0.85 for OPF). The gap is almost entirely recall. On web-crawl PII, OPF's default recall is 10%. On EHR notes it's 38%. OPF is quiet when it's unsure, and it's unsure a lot of the time.
This is consistent with how OpenAI frames the model in their release: Privacy Filter ships with a precision-tuned operating point by design, because over-redaction destroys downstream utility. The model card is explicit that the defaults are conservative and that a Viterbi calibration knob is provided for users who want to tune toward higher recall. We'll come back to that knob in a moment.
Where OPF’s PII detection falls short
A few concrete examples make the benchmark more tangible. These are synthesized to protect real customer data, but they mirror failure modes we saw in our actual test sets.
Legal documents — fax block
600 Galleria Parkway, Suite 1900 Atlanta, GA 30339 with a copy to: Priya Ramaswamy Fax No. (404) 551-8732
- OPF: Priya Ramaswamy
- Textual: Priya Ramaswamy, full address (street / city / state / zip), phone number
ASR transcript — credit card last-four
Agent: Let me take a look. So it looks like there's a Visa ending in 4427. Is that the card you want refunded?
- OPF: (no spans detected)
- Textual: Visa (organization), 4427 (credit_card_number)
Web crawl — company contact block
Contact our support team: Questions about your order can be directed to orders@brightmeadowtea.co.uk, and for wholesale inquiries please reach Priya Saldanha on +44 (0) 20 7946 0299 ...
- OPF: gets Priya Saldanha and the UK phone; misses orders@brightmeadowtea.co.uk
- Textual: all of the above
The patterns are telling. Call-center conversational phrasings ("Visa ending in 4427"), unusual email TLDs (.co.uk), and mailing blocks with the phone embedded after Fax No. are all common in real data but rarer in synthetic benchmarks. They're exactly where a model trained on synthetic PII underperforms one trained on annotated real data.
Why PII detection accuracy depends on more than the model
The most interesting question for us wasn't "does Textual win?" — honestly, our F1 scores are hard to beat. . The interesting question was why OPF misses, and what that implies for the model's usefulness as a starting point.
We ran two small experiments on the four showcase examples above.
1. Viterbi calibration sweep
OPF's output head emits per-token logits that are then decoded by a Viterbi pass with configurable transition biases. The default ships tuned for precision; we swept background_stay and background_to_start across 30 settings to see whether the missed spans could be recovered by re-tuning alone,no weight updates.
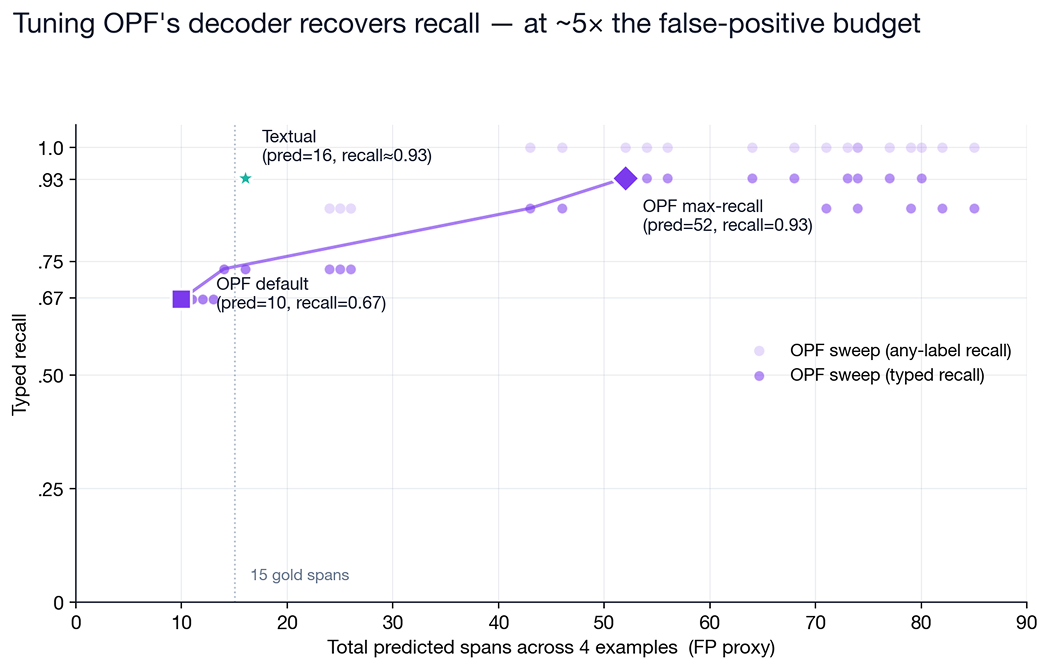
The answer is "yes, partially… — but at a cost." At aggressive bias values OPF recovers 14 of 15 gold items. To do so, it also multiplies its predictions 5×, tagging common words ("our", "please", "wholesale") as private_person and relabeling tokens that were already near the decision boundary. Textual on the same four examples hits the same 0.93 recall with 16 predictions against 15 gold items, a point that sits well above OPF's Pareto frontier.
2. Hidden-state UMAP
Lastly, we extracted pre-classifier hidden states from both OPF (640-d) and Textual (768-d) for a few thousand tokens across our test corpus, colored by Textual's fine-grained gold labels.
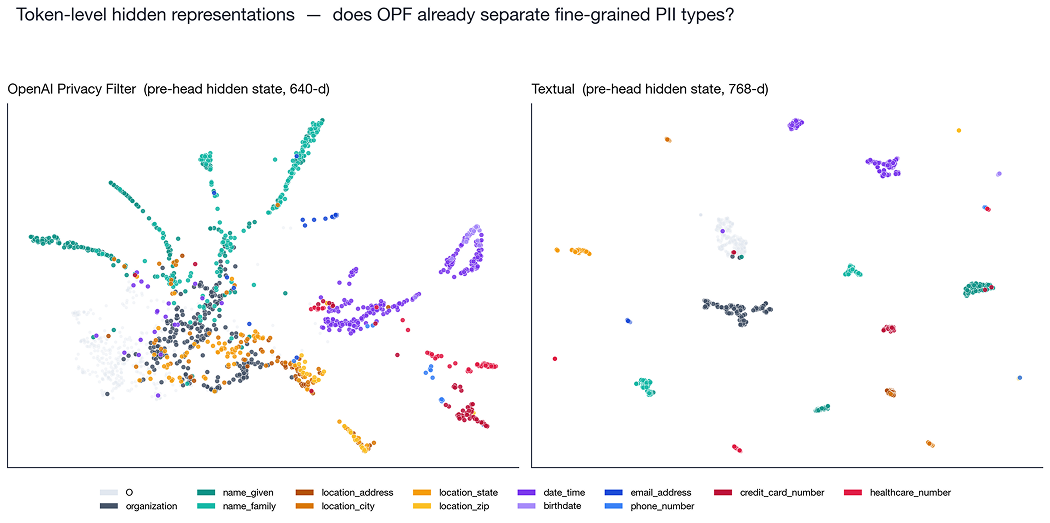
This is the finding that matters most: OPF's encoder already separates labels that its own output head cannot express. name_given and name_family form two distinct filaments on the OPF panel, even though OPF's 8-class head collapses both into private_person. Location subtypes, date vs birthdate, and credit-card vs healthcare numbers show partial separation too. The structure is there, but the head just doesn't use it.That's exactly the pattern you see in a strong base model. BERT and RoBERTa separate entity classes in their representations before they're ever fine-tuned for NER; you add a small head and some labeled data, and the classes snap into place
How much labeled data does PII detection need to match a production redactor?
If the encoder already contains the structure, how much labeled data do we need to make OPF competitive with Textual?
We projected our training artifacts from 26 labels down to OPF's 8-class space, sampled training sets of 100 / 500 / 2k / 10k documents weighted evenly across the four test domains, and fine-tuned the full model on each. Eval is on the same four test groups as the main benchmark.
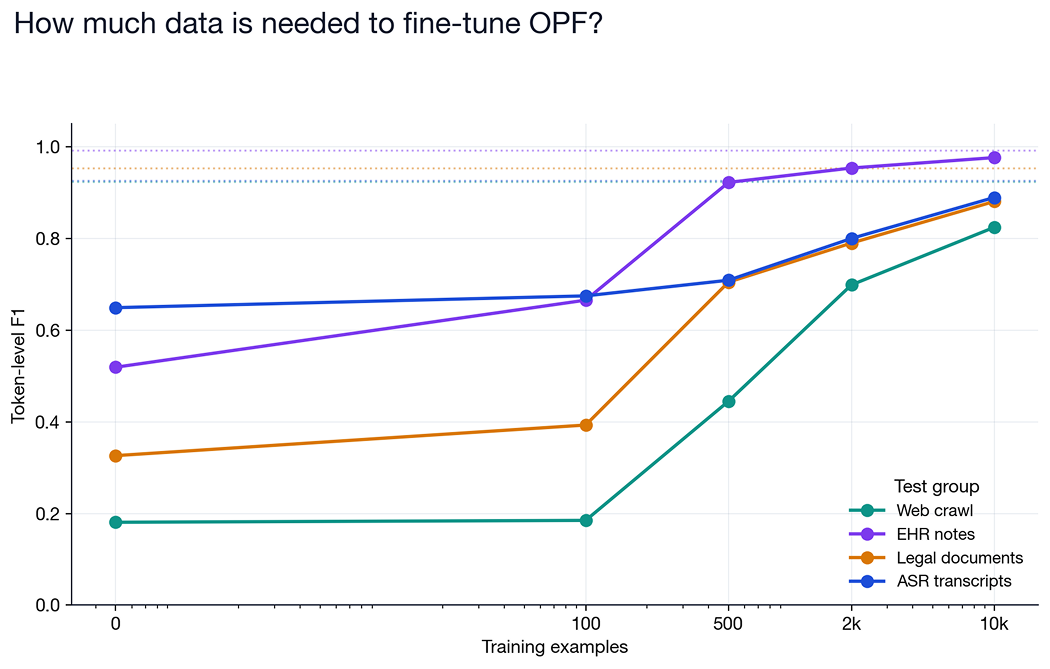
The curves tell a nuanced story:
- EHR notes closes fast. At 500 labeled documents, fine-tuned OPF reaches F1 = 0.92; at 2k it matches Textual (0.95); at 10k it's within 0.01 of Textual. If your domain looks like EHR data and you can annotate a few hundred documents, fine-tuning OPF is a very reasonable path.
- Legal and ASR transcripts ramp steadily but haven't closed the gap at 10k. Both are sitting 4–7 points below Textual after 10,000 training examples. It’s a modest gap, but a persistent one.
- Web crawl is stubborn. The jump from 0.45 at 500 to 0.82 at 10k is dramatic, but that's still 10 points below Textual. Real-world web scrapes contain a long tail of unusual PII idioms (forum-handle usernames, obfuscated contact blocks, international formats) that require lots of examples to learn.
- 100 examples barely moves the needle on any domain. Whatever your use case, "grab a couple dozen labeled docs" is not a recipe for production-grade PII detection.
The model is the easy part: why training data decides PII detection quality
Reading the benchmark in isolation, it's tempting to call this an OPF-vs-Textual story with a clear winner. That framing misses what's actually going on.
OpenAI has released a well-trained general-purpose token-classification encoder for PII. Its representations are strong, its code is clean, its license is permissive, and its small size makes it cheap to run and cheap to fine-tune. For a team that needs PII detection on data that matches the model's training distribution — short, clean text with common-format identifiers — the out-of-box checkpoint is a very reasonable choice. For a team with a specific domain and a few thousand labeled documents, fine-tuning OPF is likely to produce a competitive in-domain system at a fraction of the compute cost of training from scratch. Inference costs on the other hand are a different conversation. Textual’s fine-tuned roBERTa model can processes tens of thousands of words per second on cheap hardware, the same is not true for OPF.
What Textual brings to the same problem is the part that isn't the model: a corpus of real, representative customer-like data — EHR notes, call-center transcripts, loan documents, scraped web pages — carefully annotated by humans across a 26-label taxonomy that reflects the distinctions our customers actually need. The encoder we fine-tune is a commodity. The data is not.
The most honest conclusion we can draw from this experiment is that the model is the easy part. OpenAI has just made that part easier for everyone — including us. The hard part is still the same as it's always been: getting the right data, labeled the right way, and iterating on it until it covers the long tail of ways PII shows up in real text.
We're excited that there's now a permissively-licensed 1.5B-parameter encoder purpose-built for this task. It's one more strong option in the base-model toolbox, alongside BERT, RoBERTa, DeBERTa, and the rest. The rest of the work remains with whoever has the data.



%201.avif)

