
Synthetic data from idea to pipeline in minutes
Generate realistic data across your entire data ecosystem, then operationalize it with automated workflows and mock APIs — all through a conversational AI agent.

Trusted by thousands of developers worldwide




.svg)
For teams building at the speed of AI

New product development and feature testing
Spin up fully functional synthetic databases across multiple interconnected systems to build and test new applications and features without cross-team dependencies or compliance risk.

Reinforcement learning and AI agent training
Populate RL environments with interconnected structured databases, realistic free-text content, and live APIs to give AI agents simulated worlds to train against.

Parallel development and integration testing
Create functional mock APIs alongside the data to fuel them, unblocking frontend and backend teams and enabling comprehensive edge-case testing without waiting on live services.

Sales demos and customer onboarding
Hydrate demo environments with tailored synthetic datasets that showcase your product's capabilities, capture your audience, and speed your customers' time to value.
Built to handle real-world complexity at scale
Tonic Fabricate gives you control, connectivity, and automation across your entire data ecosystem.
Cross-system data generation
Generate referentially intact synthetic data across multiple databases, APIs, and file formats within a single agent conversation, mirroring the interconnected architecture of real-world software.
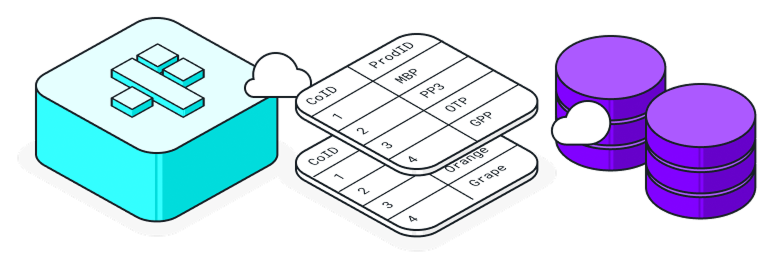
Live database connectivity
Connect directly to your production databases and generate synthetic data modeled on your real schemas, patterns, and distributions.
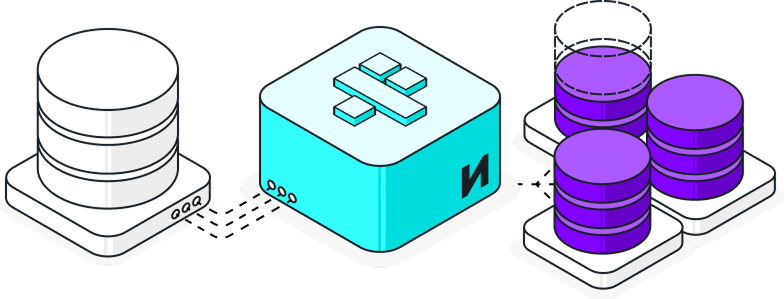
Strategic plan mode
For large or complex schemas, Fabricate analyzes your data model and drafts a multi-step generation plan before building.


Mock API creation
Upload any API spec and Fabricate builds a fully functional mock API alongside the data to fuel it, enabling parallel development and comprehensive integration testing.
Automated workflows
Define repeatable tasks, like validation, API delivery, and additional generation, as custom workflows callable via API and reusable across pipelines.
Structured ad unstructured generation
Generate relational databases, JSON, PDFs, docx files, emails, and more, all logically consistent and domain-specific.

From a prompt to production-ready data in minutes
Converse or connect
Chat with Fabricate to describe the data you need, connect live databases to model from existing data, or combine approaches across multiple systems.
View docsPlan and generate
For complex schemas, Fabricate drafts a strategic generation plan before building, dividing work into logical groups and refining the approach with you. Then watch your data come to life in real time.
View docsOperationalize
Push your data into automated workflows, stand up mock APIs from any spec, or export as CSV, PostgreSQL, MySQL, PDFs, docx, and more, in the formats your pipelines need.
View docsIterate and scale
Refine your datasets through natural language, adjust workflows, and scale your data on demand as your development and training needs evolve.
View docs











Connects to your data stack
Generate into and from PostgreSQL, MySQL, Oracle, Databricks, and more — or export as CSV, JSON, DOCX, EML, SML, SQLLite, Databricks, Snowflake, Avro, Iceberg, MongoDB, Parquet, and Amazon S3.
Full-spectrum data synthesis with the Tonic.ai product suite
Through industry-leading agentic solutions for data synthesis and de-identification, Tonic.ai provides on-demand access to realistic synthetic data for development, testing, RL environments, and AI model training. Tonic Fabricate generates synthetic data from scratch or from existing sources. Tonic Structural transforms sensitive production data into safe, high-fidelity test data. Tonic Textual redacts and synthesizes unstructured data for secure AI development. Together, the platform gives your team safe, realistic data for every workload, from local dev to production AI.
Data synthesis guides
Explore the world of data synthesis and discover how it plays a crucial role in safeguarding sensitive information while maintaining data utility in software and AI development.











Frequently asked questions
Tonic Fabricate uses an AI agent to generate high-fidelity synthetic data by interpreting natural language prompts, uploaded schemas, or existing sample data. The agent creates relationally-consistent and domain-specific datasets from scratch, allowing users to fine-tune the output in real-time to ensure it accurately mimics the complexity of real-world information.
Tonic Fabricate is primarily used to generate realistic synthetic data from scratch using an AI agent to accelerate product development, software testing, and AI model training. It also allows teams to quickly spin up domain-specific datasets for high-fidelity sales demos and to prototype new applications or agentic workflows without the need for pre-existing production data.
Tonic Fabricate can generate relationally intact structured data for databases such as PostgreSQL, MySQL, and Oracle, as well as complex, nested JSON structures. Additionally, it creates unstructured free-text data that can be exported in various formats like PDF, DOCX, and EML files.
Because Fabricate generates entirely new synthetic records, no real personal or sensitive data is exposed. This helps organizations reduce risk and support compliance with regulations like GDPR, HIPAA, and internal security policies.
Unlike TDM tools that rely on data transformations like masking, Tonic Fabricate generates net-new synthetic data on demand via an AI agent and a chat UI. Fabricate users can upload an empty schema and tailor data generation to their needs.

